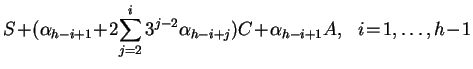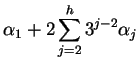In the previous cases we assumed that PEs receive data
in full for itself and all its successors.
Then, the part of the load is sent to the idle neighbors.
This is a feature of the so-called store and forward routing.
There exists a different routing strategy called circuit switching.
In circuit switching a direct (electrical) connection between the sender
and the receiver is established.
Consequently, the communication delay does not depend significantly
on the covered distance.
Hence, it can be advantageous to send some data far ahead and then
redistribute it from two (or more) points.
A similar situation takes place for some packet-switching communication
methods (e.g. wormhole routing) [NMK93].
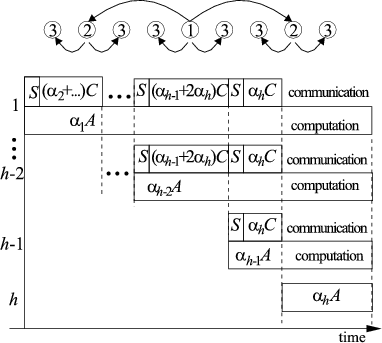
In the following we assume that the originator is located
in the center of the linear array network,
results are not returned, all PEs have network
processors and can simultaneously transmit over both ports.
The originator sends data simultaneously to two distant PEs.
In the next step both the originator and the two previously
activated PEs send data to two new processors (cf. Fig.2).
The process is repeated activating in each step twice as many processors
as were active at the beginning of the step.
We will call by a layer the set of PEs activated
in the same distribution step.
Thus, all processors are working after
![]() steps.
steps.