Narzędzia obróbki danych: Weka i RapidMiner
W pierwszej rundzie zapoznamy się z dwoma narzędziami przydatnymi w pracy każdego kopacza danych, będą to Weka i RapidMiner. Przy okazji porozmawiamy o tym, jakiego rodzaju cechy/atrybuty spotkamy w danych i w jaki sposób będziemy do nich podchodzić, żeby maestrom analizującym dane było trochę łatwiej.
Weka
- Uruchom program Weka 3.6
- Włącz moduł
Knowledge Flow - Ściągnij plik heart-c.arff (wyjaśnienie znaczenia atrybutów)
- Z zakładki DataSources wybierz operator
ArffLoaderi z menu kontekstowego wybierz opcjęConfigure…. Wskaż plik z danymi. Zmień nazwę operatora na Load data. - Z zakładki Visualization wybierz operator
TextVieweri zmień jego nazwę na View data as text. - Kliknij prawym klawiszem myszy na operatorze
ArffLoaderi z menu kontekstowego wybierz opcjędataSet. Na ekranie pojawi się niebieska linia reprezentująca przepływ danych. Kliknij na operatorzeTextVieweraby przesłać do niego dane. - Kliknij prawym klawiszem myszy na operatorze
ArffLoaderi z menu kontekstowego wybierz opcjęStart loading. Zaobserwuj w logu u dołu strony kiedy proces się zakończy. Po zakończeniu przetwarzania kliknij prawym klawiszem myszy na operatorzeTextVieweri z menu kontekstowego wybierz opcjęShow results. Przeanalizuj zawartość pliku. - Z zakładki Visualization wybierz operator
Attribute Summarizeri prześlij do niego dane z operatoraArffLoader. Ponownie uruchom przepływ i po jego zakończeniu z menu kontekstowego operatoraAttribute Summarizerwybierz opcjęShow summaries. Przeanalizuj rozkłady poszczególnych atrybutów. Czy w wyniku wizualnej inspekcji znajdujesz atrybut który może być istotnie związany z występowaniem stanu chorobowego? - Z tej samej zakładki dodaj operator
ScatterPlotMatrixi prześlij do niego dane. Ponownie uruchom przepływ i po jego zakończeniu wyświetl wynik działania operatoraScatterPlotMatrix. - Zwiększ rozmiar punktu do 3, przesuń suwak o nazwie Jitter o podobną odległość i zaktualizuj widok.
- Wybierz wykres na przecięciu atrybutów sex i chol. Zwiększ losowy rozrzut punktów i postaraj się zinterpretować wykres.
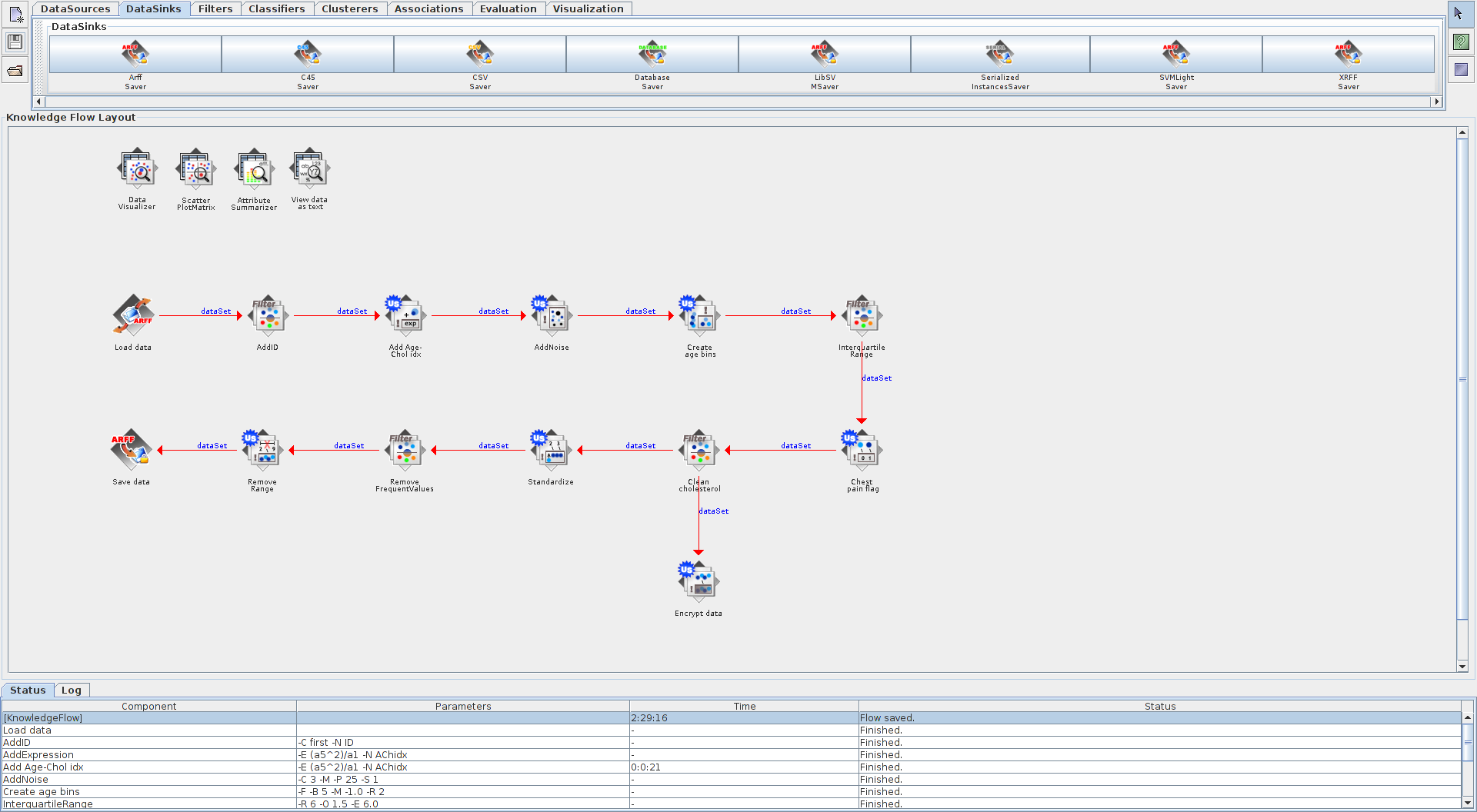
- W tej chwili Twój przepływ powinien wyglądać następująco:

- Zbiór danych nie posiada atrybutu stanowiącego klucz. Z zakładki Filters wybierz operator
AddIDi prześlij do niego dane z operatoraArffLoader. Z menu kontekstowego operatoraAddIDwybierz opcjęConfigure…i zapoznaj się z ogólną postacią okna własności operatora. Sprawdź, co kryje się za przyciskamiMoreiCapabilities - W następym kroku dodaj operator
AddExpression. Kliknij prawym klawiszem myszy na operatorzeAddIDi z menu kontekstowego wybierz opcjędataSet, a następnie prześlij dane (uzupełnione o atrybutID) do operatoraAddExpression. Otwórz okno konfiguracji operatoraAddExpressioni wprowadź formułę(a6^2)/a2. Nazwij nowy atrybut AChidx (age-cholesterol index). Zmień nazwę operatora na Add Age-Chol idx. Uruchom przepływ i obejrzyj graficznie jak wartości nowego atrybutu są skorelowane ze zmienną decyzyjną (atrybutnum). Podobny efekt możesz uzyskać za pomocą operatoraMathExpression. - Aby bardziej upodobnić nasz zbiór danych do rzeczywistych danych dodamy nieco szumu informacyjnego. Umieść w przepływie operator
AddNoisei skieruj do niego dane. Skonfiguruj operator w taki sposób, aby w trzecim atrybucie (sex) pojawiło się 25% losowych wartości. Uruchom przepływ i przy pomocy operatoraAttributeSummarizersprawdź efekt dodania szumu. - Kolejnym krokiem będzie dyskretyzacja atrybutu age na rozłączne przedziały. Umieść w przepływie operator
Discretizei prześlij do niego dane. Zmień nazwę operatora naCreate age bins. W ustawieniach operatora wskaż podział drugiego atrybutu na 5 przedziałów. Obejrzyj uzyskany wynik. Następnie wróć do ustawień operatora i zmień flagęUseEqualFrequencyna true. Zobacz, jaki tryb dyskretyzacji zadziałał teraz. - Kolejnym przydatnym operatorem do wstępnego obejrzenia danych jest operator
InterQuantileRange. Dodaj go do przepływu i prześlij do niego dane. Interesuje nas znalezienie nietypowych wartości dla atrybutu chol (szósty atrybut). Zmień parametr Outlier Factor na 1.5 i uruchom przepływ, a następnie obejrzyj wynik działania operatora korzystając z operatoraDataVisualizer(zakładka Visualization). Spróbuj podać wartość poziomu cholesterolu, po której pacjent jest uznany za wartość odstającą (ang. outlier). - Czasem zachodzi potrzeba zmiany typu atrybutu na flagę. W tym celu posłużymy się operatorem
NominalToBinaryi zmień jego nazwę naChest Pain Flag. Dodaj ten operator i prześlij do niego przepływ danych. W konfiguracji operatora wskaż do transformacji czwarty atrybut (cp, ból klatki piersiowej). Obejrzyj wynik. - Innym przydatnym operatorem jest
NumericCleaner. Umieść go w przepływie, nazwij goClean cholesteroli prześlij do niego dane. W konfiguracji operatora wskaż chęć wyczyszczenia dziewiątego atrybutu (chol) i zaproponuj zamianę wszystkich wartości bliskich 350 na wartość 350, wykorzystując wartość 10% jako próg tolerancji. - Przetwarzasz w tej chwili dane medyczne pacjentek i pacjentów. Takie dane muszą być szczególnie chronione przed niepożądanym dostępem. Wykorzystaj operator
Obfuscatew swoim przepływie i zaobserwuj wynik jego działania. Zmień nazwę operatora naEncrypt data. - W tej chwili tętno spoczynkowe jest wyrażone w uderzeniach serca na minutę. Dokonajmy przeliczenia wartości tego atrybutu w taki sposób, aby atrybut miał średnią równą 0 i odchylenie standardowe równe 1 (innymi słowy, dokonajmy standaryzacji zmiennej). Dodaj do przepływu operator
Standardizei prześlij do niego dane (prześlij dane z operatoraClean cholesteroljeśli chcesz mieć dostęp do rzeczywistych nazw atrybutów i ich wartości. Operator w rzeczywistości dokona standaryzacji wszystkich zmiennych numerycznych. Obejrzyj wynik. - W ostatnim kroku usuniemy ze zbioru niektóre przypadki. W pierwszej kolejności dodaj do przepływu operator
RemoveFrequentValuesi wskaż drugi atrybut (age). Pozostaw tylko 3 najczęściej pojawiające się wartości atrybutu age. Uruchom przepływ i zaobserwuj wynik. Następnie dodaj operatorRemovei usuń atrybuty będące flagami binarnymi reprezentującymi poszczególne typy bólu w klatce piersiowej (atrybuty 4-7). - Na końcu przejdź do zakładki DataSinks i dodaj operator
ArffSaver. Zmień nazwę operatora naSave datai prześlij do niego przepływ. W konfiguracji operatora wskaż nazwę i lokalizację pliku, do którego zapiszesz wynik. - Twój ostateczny przepływ powinien wyglądać następująco:
RapidMiner
- Uruchom program RapidMiner 6.5 i wybierz opcję utworzenia nowego procesu.
- W okienku Repositories rozwiń gałąź
Sample/data, a następnie przeciągnij i upuść na panel głównego procesu zbiór danych Golf - Połącz wyjście utworzonego operatora z wyjściem procesu
- Zapoznaj się z charakterystyką zbioru danych. Umieść kursor myszy nad wyjściem z operatora i naciśnij klawisz
F3. Powiększ wyświetlone okno. - Uruchom proces klikając na niebieski trójkąt w pasku narzędziowym lub naciskając klawisz
F11. - Sprawdź widok
Statistics - Przejdź do widoku wykresu (ang.
Charts), jako rodzaj wykresu wybierz Scatter i narysuj zależność między temperaturą i wilgotnością, z uwzględnieniem czy w dany dzień warto grać w golfa (parametr Color Column). - Powróć do widoku projektu procesu klikając na ikonę
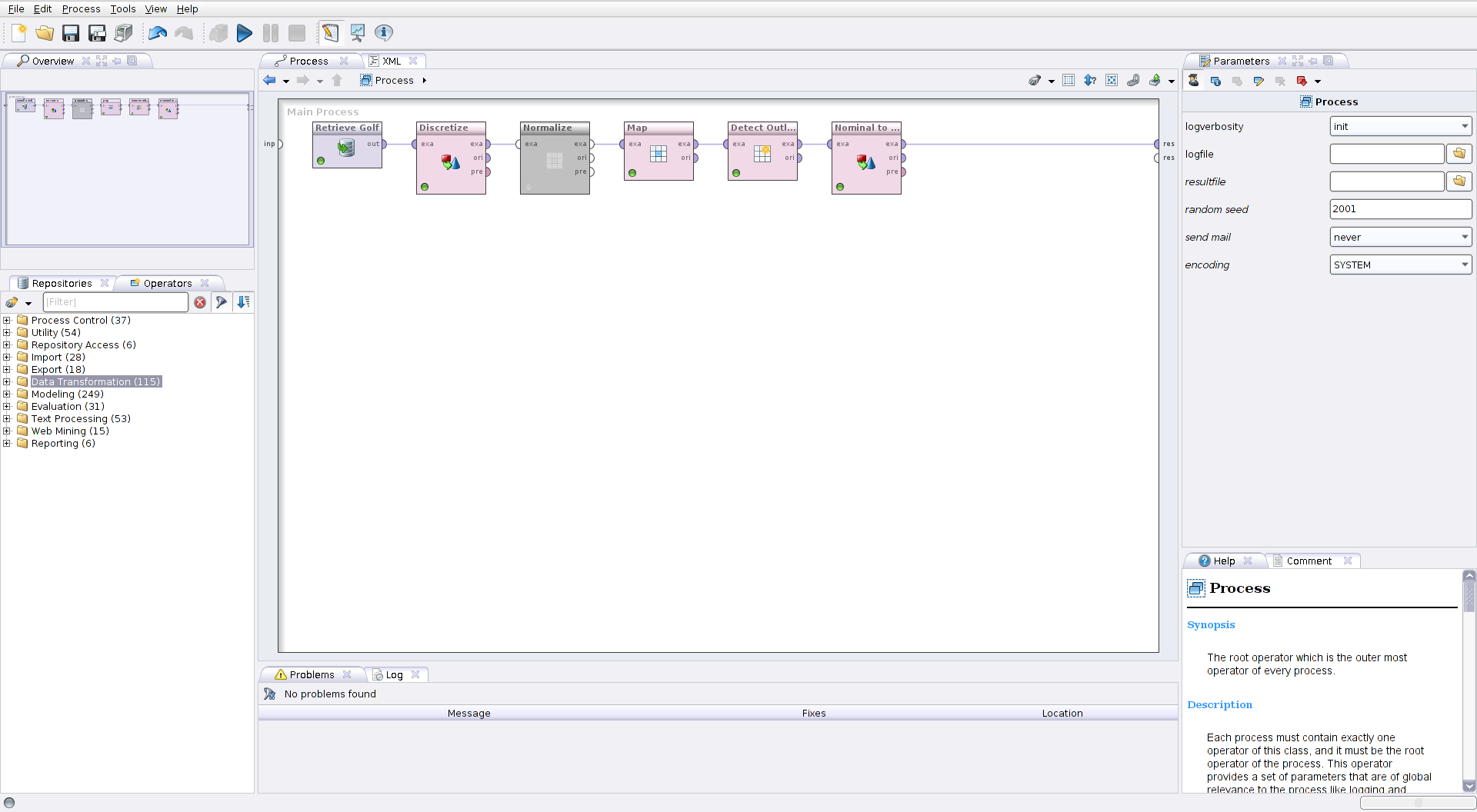
Designw pasku narzędziowym lub naciskając klawiszF8. Przejdź do zakładki Operators. W polu filtru wpisz łańcuch znaków normal. Lista dostępnych operatorów ograniczy się do dwóch pozycji. Przeciągnij operatorNormalizei upuść go na przepływ danych z operatoraRetrieve Golfdo rezultatu. Alternatywnie, możesz upuścić operatorNormalizegdziekolwiek w panelu edycji procesu, a następnie przeciągnąć przepływ danych z portu wyjściowego (out) operatoraRetrieve Golfdo portu wejściowego (exa) operatoraNormalize. W tym drugim przypadku pamiętaj, aby port wyjściowy exa operatoraNormalizepołączyć z portem wynikowym res. - Zaznacz operator
Normalize. Wskaż, że chcesz normalizować jedynie atrybuty numeryczne (attribute filter type = value_type, value type = numeric). Jako metodę normalizacji pozostawZ-transformation. Uruchom proces i zaobserwuj wynik. Czy potrafisz zgadnąć, co się stało? - Zmień rodzaj transformacji na transformację zakresową do zakresu <0,1>. Porównaj otrzymany wynik z transformacją proporcjonalną. Wyłącz operator wybierając z menu kontekstowego opcję
Enable operatorlub korzystając ze skrótu klawiszowegoCtrl+E. - Wróc do zakładki Operators i wyszukaj operatorów o nazwie
Discretize…. Najpierw użyj operatoraDiscretize by Binningaby podzielić temperaturę na trzy przedziały (chłodno, umiarkowanie, ciepło). Następnie dodaj operatorMapi za pomocą polavalue mappingsdokonaj przetłumaczenia nazw zakresów temperatury na wartości opisowe. - Wyłącz operator
Discretize by Binningi w jego miejsce wstaw operatorDiscretize by Frequency, również wskazując trzy przedziały dyskretyzacji dla atrybutuTemperature. Alternatywnie, możesz kliknąć prawym klawiszem myszy na operatorzeDiscretize by Binningi z menu kontekstowego wybrać opcjęReplace Operator, nawigując kolejno do Data Transformation/Type Conversion/Discretization/Discretize by Frequency. - Wyszukaj operator
Detect Outliers (Distance)i dodaj go do procesu. Wskaż, że detekcja wartości odstających odbywa się przez policzenie odległości do trzech najbliższych sąsiadów, oraz że w zbiorze danych występują trzy wartości osobliwe. Uruchom proces i zaobserwuj wynik. Przejdź do widoku wykresu i wybierz jako typ wykresu Scatter 3D Color. Na osiach X i Y umieść temperaturę i wilgotność, na osi Z umieść atrybut outlier, dodatkowo wykorzystując kolor do podkreślenia wartości odstających. Postaraj się znaleźć taką kombinację atrybutów, które przekonująco wskazują, że znalezione dni faktycznie odstają od reszty. - Dodaj do procesu operator
Nominal to Binominali wskaż atrybut Outlook jako atrybut do transformacji. - Twój ostateczny proces powinien wyglądać następująco:
- Uruchom proces i sprawdź wyniki. Ile jest teraz atrybutów?
- W ostatnim kroku zobaczymy obsługę wartości brakujących w RapidMinerze. Wyłącz wyświetlanie wyniku przetwarzania poprzedniego przepływu, a następnie dodaj operator wczytujący zbiór danych Labor Negotiations (znajduje się w przykładowych danych). Wyświetl zbiór i obejrzyj metadane. Zwróć uwagę na liczbę brakujących wartości w poszczególnych atrybutach.
- Użyj operatora
Replace Missing Valuesaby zamienić wszystkie brakujące wartości na wartość -1. - Oryginalne dane z portu wyjściowego operatora
Replace Missing Valuesprześlij do operatoraImpute Missing Values. Wyłącz opcjęlearn on complete casesi wskaż losową kolejność przetwarzania rekordów ze zbioru. Zauważ, że operatorImpute Missing Valuesjest operatorem dominującym, tj. zawiera w sobie inny operator. Wejdź do wewnątrz operatoraImpute Missing Valuesi jako metodę wyznaczania zamiennika wartości brakującej wybierz operatork-NN. Skonfiguruj operator w taki sposób, aby wartość brakująca była uzupełniana w oparciu o trzech najbliższych sąsiadów i wyliczana za pomocą zmodyfikowanej odległości euklidesowej. - Wyślij wyniki działania obu operatorów (
Replace Missing ValuesiImpute Missing Values) na wyjście procesu. Porównaj wykresy histogramów dla atrybutustandby-pay.
Manuskrypty i księgi

obowiązkowe
- notka blogowa o normalizacji
- wprowadzenie do wstępnego przetwarzania danych, Hyon Gyu Lee, Chungbuk National University, Korea
opcjonalne
- Chapter 3 "Data Preprocessing", Jiawei Han, Micheline Kamber and Jian Pei, Data Mining: Concepts and Techniques, 3rd Edition
- "Data cleaning: Problems and current approaches." Rahm, Erhard, and Hong Hai Do. IEEE Data Engineering Bulletin 23.4 (2000): 3-13.
- Data Cleaning Material Collection, obszerna lista dostępnej literatury na temat czyszczenia danych
