Maszyny wektorów nośnych
W ramach dzisiejszych zajęć poznamy popularną w ostatnich latach metodę eksploracji danych Support Vector Machines. Przy okazji obejrzymy jeszcze raz krzywą lift oraz krzywą ROC (ang. Receiver Operating Characteristic).
Rapid Miner
- Uruchom narzędzie Rapid Miner 6.5
- Utwórz przepływ polegający na wczytaniu pliku bank.csv i zbudowaniu klasyfikatora
SVM. Zapoznaj się z opisem zbioru danych. Wczytaj dane za pomocą operatoraRead CSVi prześlij je do operatoraNominal to Numerical, zamieniając atrybuty nominalne na numeryczne zgodnie z metodą unique integers. Wewnątrz operatoraSplit Validationumieść operatorSVMi wykorzystaj początkowo kernel dot (możesz też poeksperymentować z innymi rodzajami kerneli). Obejrzyj uzyskany model. Zwiększ wartość parametruCzezwalając na pewną elastyczność granicy decyzyjnej. Możesz manipulować modelem także za pomocą parametrówL posiL neg, które działają analogicznie do funkcji kosztu. - Co zrobić w przypadku gdy klasyfikowany zbiór danych ma więcej niż dwie klasy? Załaduj plik letter-recognition.csv i zapoznaj się z jego opisem. Ponieważ plik jest dośc duży, użyj operatora
Sample (Stratified)do wylosowania 10% danych. Prześlij je do operatoraSplit Validation, wewnątrz którego umieść operatorPolynomial by Binominal Classificationwykorzystujący we wnętrzu operatorSVM. Sprawdź, która z metod (1-against-all, 1-against-1, ECOC) daje najlepsze rezultaty.
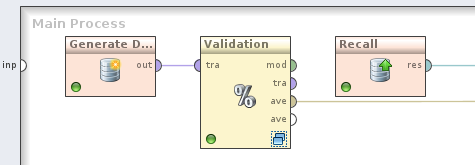
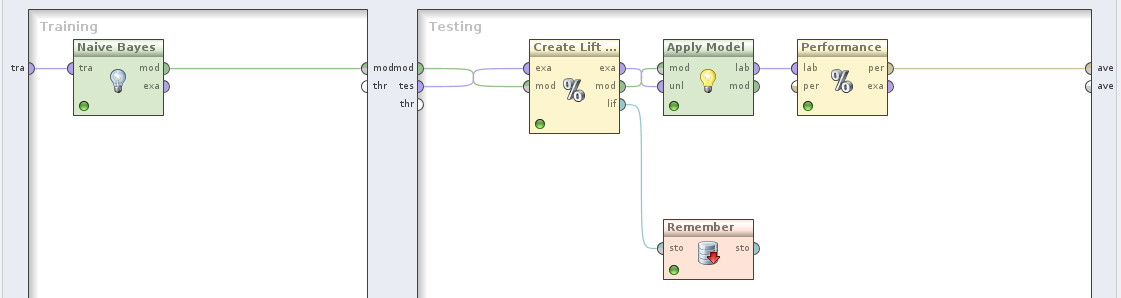
- Utwórz przepływ obrazujący wykorzystanie krzywej lift. Użyj operatora
Generate Direct Mailing Dataw celu wygenerowania 1000 syntetycznych rekordów. Prześlij wygenerowany zbiór uczący do operatoraSplit Validation. Wewnątrz operatoraSplit Validationwykorzystaj w fazie uczenia operatorNaive Bayes, natomiast w fazie testowania umieść kolejno: operatorCreate Lift Chart, operatorApply Modeloraz operatorPerformance (Classification). Dodatkowo, portliftoperatoraCreate Lift Chartprześlij do operatoraRememberi zapisz w repozytorium pod dowolną nazwą (jako wartośćio objectwybierz LiftParetoChart). W procesie nadrzędnym dodaj operatorRecalli odczytaj obiekt zapisany w trakcie walidacji modelu, wysyłając go jako końcowy wynik przepływu. Jeśli chcesz, możesz też wyświetlić zbiór uczący (porttraoperatoraValidation). Aby upewnić się, że operatory są wykonywane we właściwej kolejności, wybierz z menu opcjęProces - Operation Execution Order - Order Executioni w razie konieczności popraw przepływ: walidacja klasyfikatora musi się odbyć przed operatoremRecall.
- Utwórz podstawowy przepływ obrazujący wykorzystanie krzywej ROC. Odczytaj z repozytorium zbiór danych
Sonari wyślij go do operatoraSplit Validation. Wewnątrz operatora do walidacji w fazie uczenia wykorzystaj operatorSupport Vector Machine (LibSVM), a w fazie testowania użyj kolejno: operatoraApply Model, operatoraFind Threshold, operatoraApply Threshold, a w końcu operatoraPerformance.

- Ostatnim przepływem jest przepływ obrazujący możliwość jednoczesnego porównania wielu krzywych ROC pochodzących od różnych klasyfikatorów. Odczytaj zbiór danych
Sonar, a następnie dodaj operatorAdd Noise. Nie dodawaj nowych atrybutów, ale wprowadź 5% szum we wszystkich atrybutach. Tak zmodyfikowany zbiór uczący wyślij do operatoraCompare ROCs. Wewnątrz tego operatora umieść operatoryNaive Bayes,Decision TreeorazSupport Vector Machines. PortrocoperatoraCompare ROCswyślij jako wynik przepływu. Obejrzyj i porównaj krzywe ROC klasyfikatorów.
Oracle Data Mining
- Zaloguj się do bazy danych: iSQLPlus korzystając z konta ED_XX. Identyfikator połączenia to DBLAB01.
- Pobierz skrypt education_spending.sql i uruchom go na swoim koncie.
- Zapoznaj się ze strukturą i zawartością zbioru danych
DESCRIBE education_spending SELECT * FROM education_spending;
- Usuń tabelę do normalizacji atrybutów numerycznych
DROP TABLE normalization;
- Jeśli wykonywała(e)ś wcześniej to ćwiczenie, to usuń perspektywę pokazującą dane po normalizacji
DROP VIEW v_prepared;
- Znormalizuj atrybuty
RESIDENTS,INCOME,UNDER18, iEXPENDITURE.
BEGIN -- utworzenie tabeli do przechowywania parametrow normalizacji DBMS_DATA_MINING_TRANSFORM.CREATE_NORM_LIN ( norm_table_name => 'normalization'); -- normalizacja za pomoca metody min-max DBMS_DATA_MINING_TRANSFORM.INSERT_NORM_LIN_MINMAX ( norm_table_name => 'normalization', data_table_name => 'education_spending', exclude_list => DBMS_DATA_MINING_TRANSFORM.COLUMN_LIST('ID','STATE','REGION')); -- utworzenie perspektywy pokazujacej znormalizowane dane DBMS_DATA_MINING_TRANSFORM.XFORM_NORM_LIN ( norm_table_name => 'normalization', data_table_name => 'education_spending', xform_view_name => 'v_prepared'); END;
- Usuń tabelę do przechowywania ustawień algorytmu
DROP TABLE settings;
- Utwórz na nowo tabelę do przechowywania ustawień i wstaw do niej parametry algorytmu SVM
ALTER SESSION SET NLS_LANGUAGE = english; ALTER SESSION SET NLS_NUMERIC_CHARACTERS = ".,";
CREATE TABLE settings ( setting_name VARCHAR2(30), setting_value VARCHAR2(30));
BEGIN INSERT INTO settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_support_vector_machines); INSERT INTO settings (setting_name, setting_value) VALUES (dbms_data_mining.svms_kernel_function, dbms_data_mining.svms_linear); INSERT INTO settings (setting_name, setting_value) VALUES (dbms_data_mining.svms_conv_tolerance, 0.002); INSERT INTO settings (setting_name, setting_value) VALUES (dbms_data_mining.svms_outlier_rate, 0.1); COMMIT; END;
- Jeśli już wykonywała(e)ś wcześniej to ćwiczenie, usuń stary model klasyfikatora z repozytorium
BEGIN DBMS_DATA_MINING.DROP_MODEL('SVM_Outlier'); EXCEPTION WHEN OTHERS THEN NULL; END;
- Zbuduj model klasyfikatora wykorzystując do tego celu zbiór danych
v_prepared. Zauważ, że parametrtarget_column_nameprzyjmuje wartośćNULL, co oznacza uruchomienie wersji one-class algorytmu SVM.
BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'SVM_Outlier', mining_function => dbms_data_mining.classification, data_table_name => 'v_prepared', case_id_column_name => 'id', target_column_name => NULL, settings_table_name => 'settings'); END;
- Wyświetl ustawienia i sygnaturę modelu
SELECT setting_name, setting_value FROM TABLE(DBMS_DATA_MINING.GET_MODEL_SETTINGS('SVM_Outlier')) ORDER BY setting_name; SELECT attribute_name, attribute_type FROM TABLE(DBMS_DATA_MINING.GET_MODEL_SIGNATURE('SVM_Outlier')) ORDER BY attribute_name;
- Wyświetl listę stanów wraz ze wskaźnikiem odbiegania od średniej
SELECT id, state, region, income, residents, under18, expenditure, prediction_probability(SVM_Outlier, 0 using *) AS outlier_pred FROM v_prepared ORDER BY prediction_probability(SVM_Outlier, 0 using *) DESC;
Zadanie samodzielne
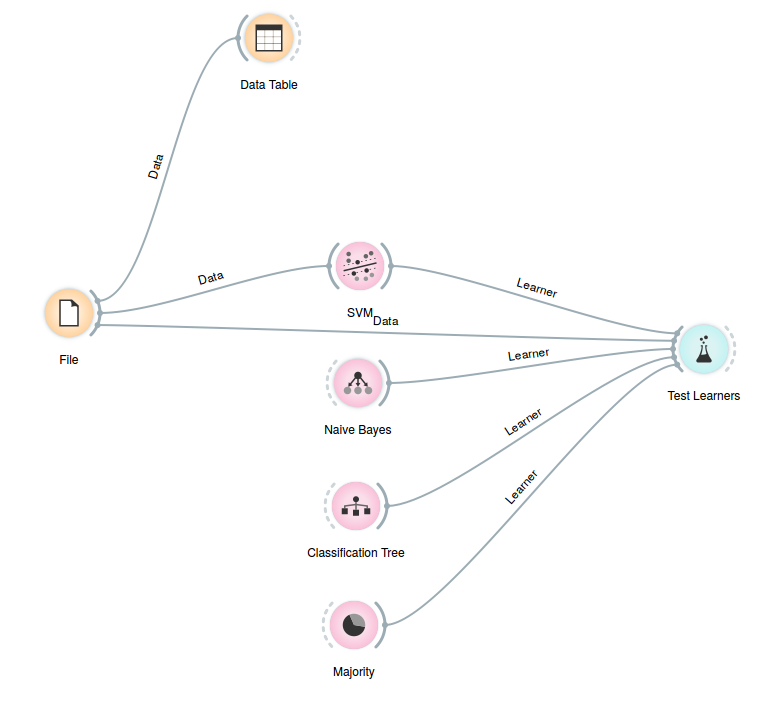
Użyj narzędzia Orange Data Mining do skonstruowania przepływu obrazującego wykorzystanie algorytmu SVM. W tym celu załaduj dostarczony wraz z narzędziem zbiór danych heart_disease.tab i obejrzyj jego zawartość, a następnie przetestuj operator SVM porównując go z operatorami Majority, Decision Tree oraz Naive Bayes. Postaraj się zmodyfikować przepływ (parametry, dodatkowe operatory) tak, aby uzyskać dokładność większą niż najlepszy z tych algorytmów.
Początkowy przepływ powinien wyglądać tak:
Manuskrypty i księgi

- Introduction to Support Vector Machines, D.Boswell
- An Introduction to Support Vector Machines for Data Mining, R.Burbidge, B.Buxton, Proc. 12th Conference Young Operational Research (YOR12), Nottingham, UK, 2011
- Support Vector Machines Explained, T.Fletcher, 2009
