Ocena ważności atrybutów
Na tych zajęciach przedstawione zostaną metody oceny przydatności poszczególnych atrybutów w procesach eksploracji danych. W trakcie laboratorium zapoznajemy się z podstawowymi metodami identyfikacji atrybutów, które są nieprzydatne w zadaniach eksploracji. Będziemy badać zmienność wewnątrz atrybutów, korelację między atrybutami, a także będziemy wybierać zbiory atrybutów charakteryzujące się najbardziej pożądanymi cechami.
Rapid Miner
- Uruchom narzędzie RapidMiner 6.5
- Utwórz nowy przepływ i załaduj przykładowy zbiór danych Sonar. Zapoznaj się z charakterystyką zbioru danych.
- Dodaj za operatorem
RetrieveoperatorMultiply. - Utwórz przepływ usuwający silnie skorelowane atrybuty. W tym celu dodaj operator
Remove Correlated Attributesi usuń wszystkie atrybuty które są skorelowane powyżej progu 0.75. Dodaj do przepływu operatorCorrelation Matrixłącząc go z portem wyjściowymorioperatoraRemove Correlated Attributes. Czy operator jest całkowicie deterministyczny? - Utwórz przepływ usuwający atrybuty o małej zmienności. Dodaj operator
Remove Useless Attributesi usuń te atrybuty, w których zmienność wartości jest poniżej 0.1. Uruchom przepływ, a następnie sprawdź czułość metody na zmianę progu zmienności. - Utwórz przepływ dokonujący ważenia atrybutów na podstawie miary Relief. W tym celu dodaj operator
Weight by Reliefi ustaw liczbę sąsiadów na 10 (pozostaw normalizację wag). Następnie umieść na przepływie operatorSelect by Weightsi wybierz tylko te atrybuty, których waga jest większa niż 0.5. Uruchom przepływ i sprawdź, w jaki sposób zmiana liczby sąsiadów lub zmiana progu akceptacji wag wpłynie na liczbę wybranych atrybutów. Zamień operatorWeight by Reliefna operatorWeight by Rule, uruchom zmodyfikowany przepływ i porównaj uzyskane wyniki. - Utwórz przepływ dokonujący ważenia atrybutów na podstawie statystyki Chi-kwadrat. Przypomnij sobie, co wyznacza test Chi-kwadrat. Dodaj operator
Weight by Chi Squared Statistici powiązany z nim operatorSelect by Weights. Zmień liczbę przedziałów dyskretyzacji w operatorzeWeight by Chi Squared Statisticna 5 i na 20, porównaj wyniki.
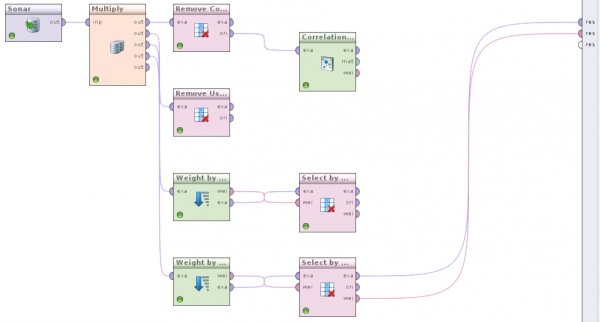
Twój ostateczny przepływ powinien wyglądać następująco:
Orange Data Mining
- Utwórz nowy przepływ, umieść na nim operator
Filei wczytaj zbiór danychTic-Tac-Toe. Zapoznaj się z opisem zbioru danych. - Prześlij dane do operatora
Rank. Pozostaw jedynie miarę ReliefF i znajdź 3 najważniejsze pozycje w grze decydujące o wygranej. - Sprawdź, czy zmiana liczby najbliższych sąsiadów, względem których liczona jest miara ReliefF wpływa na wynik.
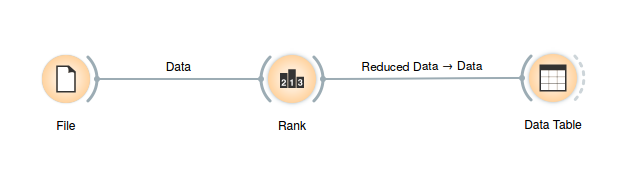
Twój ostateczny przepływ powinien wyglądać następująco:
Weka
- Uruchom narzędzie Weka Explorer
- Wczytaj zbiór danych spambase_real.arff
- Zastosuj filtr który zamieni ostatni atrybut (zmienną celu) na zmienną kategoryczną.
- Przejdź do zakładki Select Attributes. Następnie porównaj wyniki dwóch metod:
- ocena CfsSubsetEval z metodą przeszukiwania przestrzeni rozwiązań BestFirst
- ocena ReliefAttributeEval z metodą przeszukiwania przestrzeni rozwiązań Ranker
Manuskrypty i księgi

opcjonalne
- Wprowadzenie do metod wyboru cech
- Isabelle Guyon, Introduction to feature selection (VideoLectures.net)
- I.Guyon, An introduction to variable and feature selection, The Journal of Machine Learning Research, 2003
- Minimum Description Length on the Web: największe centrum informacji o MDL
- MDL w Wikipedii
- Obszerne wprowadzenie do MDL na Scholarpedii
