Meta-metody klasyfikacji
W tej rundzie poznajemy meta-metody uczenia maszynowego. Dowiadujemy się, czy bezpośrednia demokracja (Voting) jest lepsza niż demokracja sterowana (Stacking) i dowiadujemy się, jak zastosować klasyfikator binarny do klasyfikacji danych zawierających więcej niż dwie klasy. A przede wszystkim uczymy się oszczędzać sobie czas wykonując setki eksperymentów za jednym pociągnięciem myszki.
Rapid Miner
- Uruchom narzędzie Rapid Miner 6.5
- Utwórz przepływ ilustrujący metodę Bagging. W tym celu załaduj zbiór mushroom.csv (opis: mushroom.arff) i prześlij do operatora
Set Role, wskazując atrybut class jako zmienną celu. Następnie prześlij zbiór danych do operatoraSplit dataw celu podzielenia zbioru na dwie partycje w proporcji 70%-30%. Prześlij większą część zbioru uczącego do operatoraBagging. Wykonaj 10 iteracji uczenia drzewa decyzyjnego (użyj miary Gini index), wykorzystując w każdej iteracji 90% danych jako zbiór uczący. Model wynikowy wyślij do operatoraApply Modela jako zbiór testowy wykorzystaj owe 30% oryginalnych danych które nie było wykorzystywane do uczenia klasyfikatora. Wykorzystaj operatorPerformancedo znalezienia dokładności klasyfikatora końcowego. Sprawdź, jaki wpływ na dokładność klasyfikacji ma zmieniająca się liczba iteracji (tj. niezależnie budowanych modeli). - Utwórz przepływ wykonujący algorytm AdaBoost. Pobierz zbiór danych nursery.csv (opis: nursery.arff) i za pomocą operatora
Set Rolewskaż atrybut class jako zmienną decyzyjną. Prześlij zbiór danych do operatoraSplit Validationpozostawiając domyślne parametry tego operatora. W fazie uczenia operatoraSplit Validationumieść meta-operatorAdaBoost, a wewnątrz tego operatora umieść naiwny klasyfikator Bayesa. W fazie testowania operatoraSplit Validationumieść tradycyjnie operatoryApply ModelorazPerformancew celu określenia dokładności klasyfikacji. Porównaj uzyskany wynik z sytuacją w której zamiast operatoraAdaBoostwykorzystujesz bezpośrednio naiwny klasyfikator Bayesa. Powtórz ten sam eksperyment wykorzystując tym razem jako klasyfikator operatorRule Induction. Czy procedura adaptive boosting w tym przypadku polepszyła dokładność klasyfikacji? - Pobierz zbiór danych breast-cancer.csv (opis: breast-cancer.arff), zmienną decyzyjną jest Class. Utwórz przepływ realizujący proste głosowanie. Wyślij dane do operatora
Split Datai podziel je w proporcji 70%-30%. Większy zbiór prześlij do operatoraVote, wewnątrz którego umieść klasyfikatoryRule Induction,Naive Bayes ClassifierorazDecision Tree. Model wynikowy wyślij do operatoraApply Modela jako zbiór testowy wykorzystaj dane nieużyte do uczenia klasyfikatorów. Jaka jest dokładność takiego klasyfikatora? Czy jest on lepszy niż indywidualne klasyfikatory? Twój ostateczny przepływ powinien wyglądać tak:
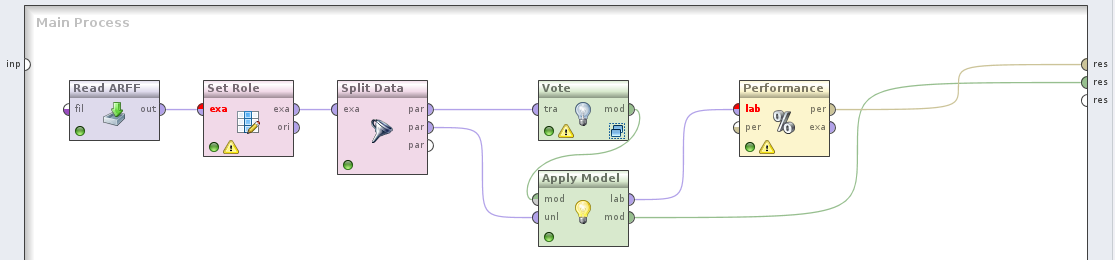
- Zamień głosowanie na operator
Stacking, umieszczając w fazie Stacking Model Learner operatorRule Induction, oraz zamieniając naiwny klasyfikator Bayesa na operatorCHAID. Uruchom przepływ i obejrzyj modele bazowe. - W ostatnim przykładzie postaramy się przeszukać przestrzeń parametrów w celu znalezienia optymalnych wartości. Pobierz ponownie zbiór letter.csv (opis: letter.arff) i prześlij go do operatora
Optimize Parameter (Grid). Wewnątrz operatora umieść operatorSplit-Validationzawierający w fazie uczenia operatorNeural Net, a w fazie testowania tradycyjną kombinację operatorówApply ModeliPerformance (Classification). Port wyjściowy ave operatoraValidationprześlij do operatoraLogi zapisz pod dowolną nazwą na dysku. W konfiguracji operatoraLogzaznacz zapisywanie dokładności (wartość z operatoraPerformance), momentu (parametr z operatoraNeural Net) i tempa uczenia (parametr z operatoraNeural Net). Konfiguracja operatoraLogpowinna wyglądać następująco:
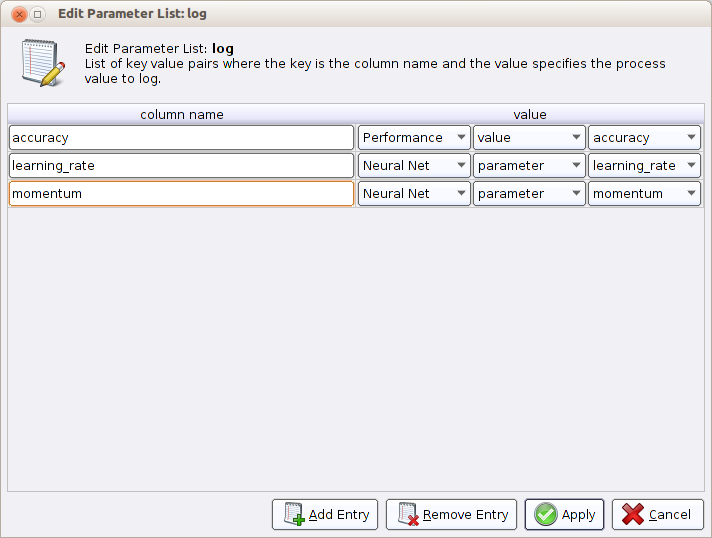
- Wróć do konfiguracji operatora
Optimize Parameter (Grid). Kliknij przycisk Edit Parameter Settings i z listy dostępnych operatorów wybierz operatorNeural Net, a następnie wybierz dwa parametry operatora:learning_rateimomentum. Przenieś oba parametry do panelu Selected Parameters. Zaznacz parametrlearning_ratei wskaż, że powinien się zmieniać od 0 do 1 w 4 krokach. Analogicznie, skonfiguruj parametrmomentumaby się zmieniał od 0 do 1 w 4 krokach (w obu przypadkach zwiększanie wartości parametru w każdym kroku powinno być liniowe). Liczbę cykli uczenia sieci neuronowej ustaw kolejno na 5, 10 i 15. Okno konfiguracji operatoraOptimize Parameter (Grid)powinno wyglądać następująco:
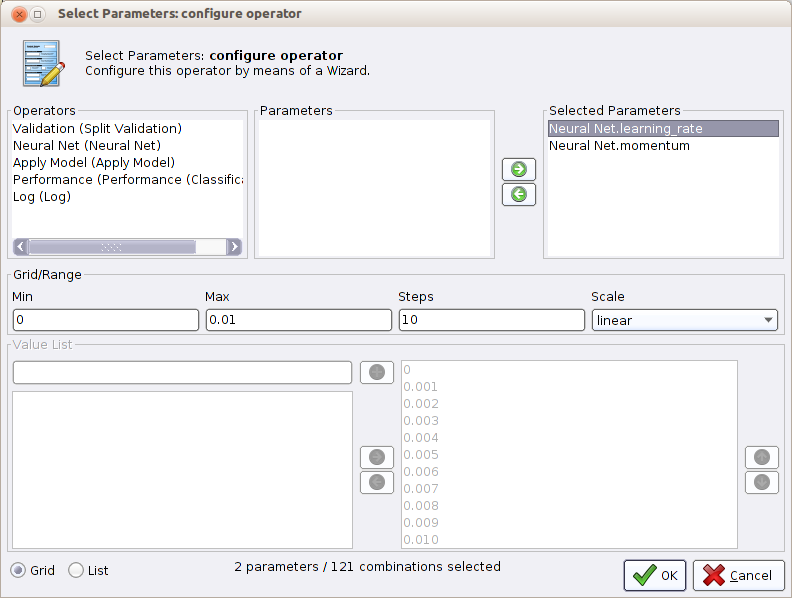
- Przejdź jeszcze do konfiguracji operatora
Neural Neti zmniejsz liczbę rund uczenia sieci do 5. Wyłącz także normalizację i mieszanie danych wejściowych. Uruchom przepływ a następnie skorzystaj z wizualizacji Surface 3D w celu obejrzenia wyników.
Zadanie samodzielne
Pobierz zbior danych onehr.csv reprezentujący dane dotyczące stanu powłoki ozonowej. Zapoznaj się z opisem danych. Wykorzystując automatyczną optymalizację przestrzeni parametrów postaraj się uzyskać najwyższą możliwą dokładność klasyfikatora (accuracy). Możesz posłużyć się dowolnym klasyfikatorem.
Manuskrypty i księgi

- Ensemble Learning, T.G. Detterich, The Handbook of Brain Theory and Neural Networks, Cambridge, MA
- A brief introduction to boosting , R.E. Schapire, Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence, 1401-1406, 1999
- Bagging predictors, L. Breiman, Machine Learning Volume 24, Number 2, 123-140, DOI: 10.1007/BF00058655
- An Empirical Comparison of Voting Classification Algorithms: Bagging, Boosting, and Variants, E. Bauer, R. Kohavi, Machine Learning Volume 36, Numbers 1-2, 105-139, DOI: 10.1023/A:1007515423169
