Analiza skupień
Celem laboratorium jest zapoznanie studentów z podstawowymi pojęciami związanymi z analizą skupień: pojęciem miary odległości, dostępnymi miarami odległości, oraz algorytmami k-średnich, algorytmami opartymi na gęstości, oraz algorytmami opartymi na zasadzie EM (ang. expectation maximization).
Rapid Miner
- Uruchom narzędzie Rapid Miner 6.5
- Utwórz przepływ polegający na wczytaniu zbioru danych
Irisi zbudowaniu modelu analizy skupień za pomocą bliźniaczych algorytmów k-Means i k-Medoids. Przed uruchomieniem algorytmów analizy skupień zredukuj liczbę wymiarów oryginalnego zbioru danych do 2 wymiarów (możesz się posłużyć np. operatoremSingular Value Decomposition). Obejrzyj uzyskane wyniki na wykresie. Postaraj się znaleźć różnice między modelami produkowanymi przez oba algorytmy. Sprawdź, jaki wpływ na czytelność modelu ma manipulowanie wartością parametruk(liczba skupień). - Utwórz przepływ, którego pierwszym krokiem jest wygenerowanie losowego zbioru danych (operator
Generate Data, funkcja checkboard classification). Pozostaw liczbę generowanych przykładów równą 100. Prześlij wygenerowany zbiór danych do operatoraLoop and Deliver Best. Wewnątrz tego operatora umieść wywołanie algorytmu k-Means, a znaleziony model prześlij do operatoraCluster Distance Performance. Jako kryterium oceny podziału przyjmij średnią odległość od centroidu skupienia. Wyniki każdej iteracji zapisz za pomocą operatoraLog. - Utwórz przepływ, który zobrazuje sposób wyboru optymalnej wartości parametru k. Zbiór danych
Iriswyślij do operatoraLoop Parameters. Wewnątrz operatora umieść sekwencję operatorówK-Means,Cluster Distance PerformanceorazLog. Do pliku logu zapisz wartość parametru k (Clustering:parameter:k) oraz uzyskane wyniki (Performance:value:avg_within_distance i Performance:value:DaviesBouldin). W operatorzeLoop Parametersustaw iterowanie po wartościach parametru k w zakresie 2-13 (parametr steps pozostaw ustawiony na wartość 10). - Utwórz przepływ ilustrujący algorytm analizy skupień bazujący na lokalnej gęstości sąsiedztwa, wykorzystując do tego celu algorytm
DBScan. Wykorzystaj operatorGenerate Datado zbudowania trzech koncentrycznych pierścieni punktów. Prześlij zbiór danych do operatoraNormalizewykorzystując normalizację przez odchylenia standardowe. Tak przygotowane dane prześlij do operatoraDBScan, podając jako promień sąsiedztwa epsilon=0.5 i min points=5. Obejrzyj uzyskany wynik (użyj atrybutu cluster do kolorowania przykładów na wykresie). Zobacz, co się stanie, jeśli zmienisz epsilon na 0.2. Na koniec zamień operatorDBScannaK-Meansi obejrzyj wynik. Czy potrafisz go wytłumaczyć? - Utwórz przepływ wykorzystujący generator danych syntetycznych (operator
Generate Data, funkcja random) i wygeneruj zbiór 1000 przykładów w przestrzeni 2-wymiarowej. Zastosuj do zbioru danych operatorExpectation Maximization Clusteringz parametrem k=3. Sprawdź, jaki efekt na wynik końcowy ma zmiana wartości parametru initial distribution z k-średnich na losowy przydział przypadków.
Orange Data Mining
- Uruchom narzędzie Orange Data Mining
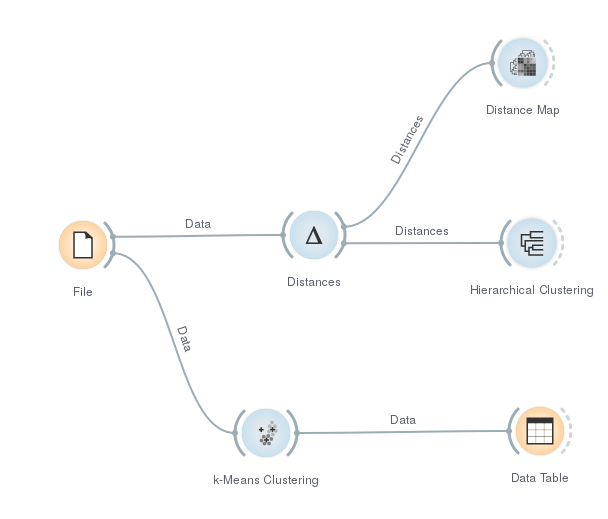
- Umieść na przepływie operator
Filei wczytaj zbiór danychzoo.tab - Wykorzystaj operator
Distancesdo wyznaczenia odległości między poszczególnymi obiektami. Następnie prześlij znalezioną macierz odległości do operatoraDistance Mapi sprawdź, jak sposób sortowania macierzy wpływa na jej interpretowalność. - Wyślij znalezioną macierz odległości do operatora
Hierarchical Clusteringi obejrzyj uzyskany dendrogram. Sprawdź wpływ sposobu łączenia skupień (linkage) na wynikowy dendrogram. - Prześlij dane do operatora
k-Means Clustering, ustalając zmienną liczbę grup między 2 a 10. Zobacz, czy znaleziona liczba skupień zależy od przyjętej miary jakości (scoring) - Wyślij wynik do operatora
Data Tablei posortuj dane według przydzielonego numeru skupienia. Zobacz, czy zmiana sposobu inicjalizacji centroidów skupień wpłynie na końcowy wynik. - Twój ostateczny przepływ powinien wyglądać tak: