Przygotowanie przed zajęciami
Na najbliższe zajęcia proszę zapoznać się z poniższymi materiałami, w szczególności opanować działanie algorytmu eliminacji kandydatów.
Komentarz wideo
Całość zajęć omówiona
tutaj.
Dane do zadań obliczeniowych
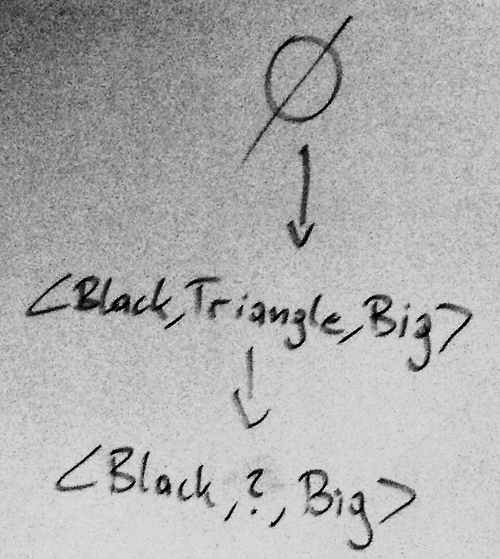
Problem 1. Learning the concept of "Suitable figures"
| Color |
Shape |
Size |
Decision |
| Black |
Triangle |
Big |
Positive |
| White |
Triangle |
Small |
Negative |
| Black |
Circle |
Big |
Positive |
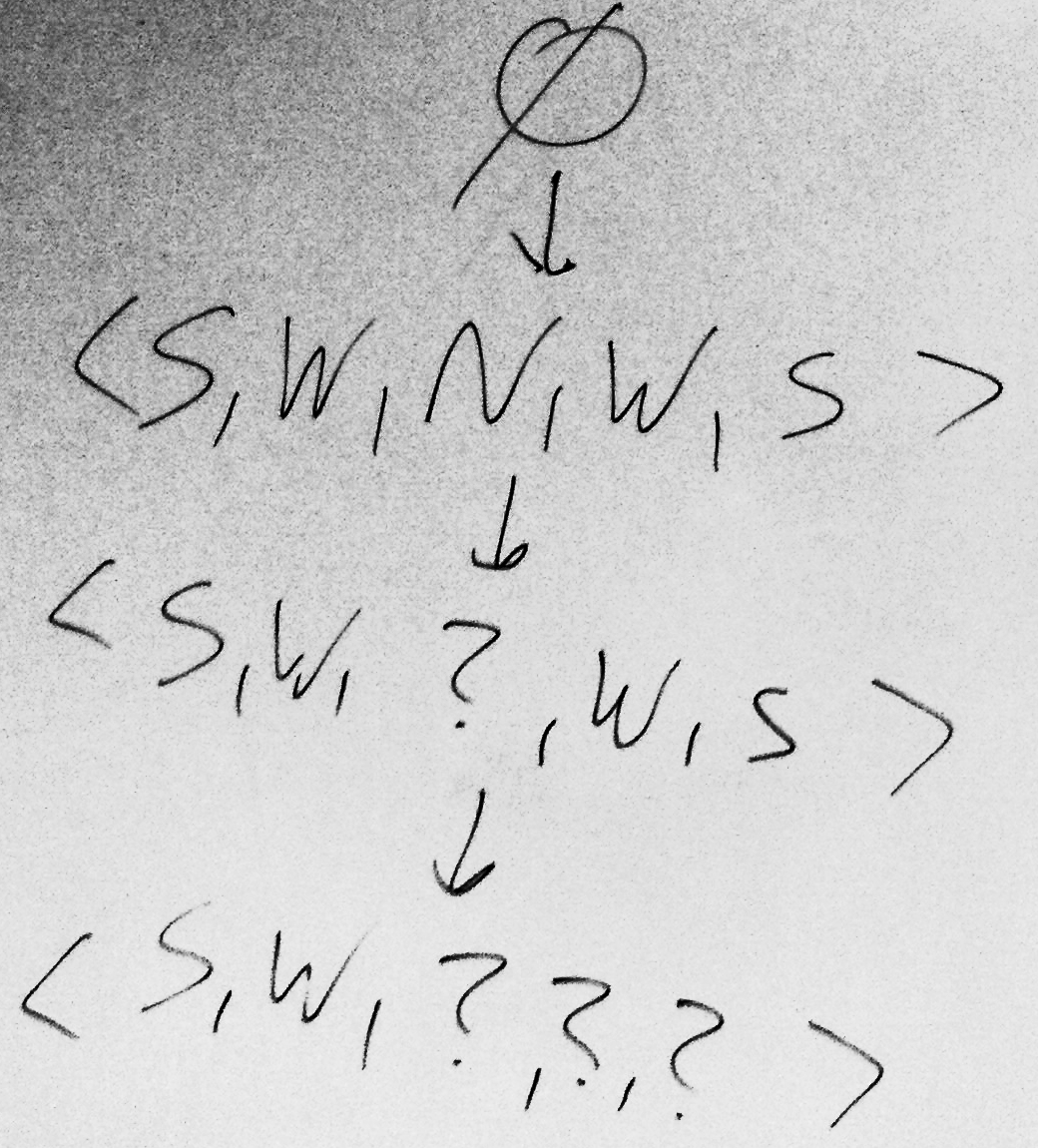
Problem 2. Learning the concept of "Good water-sport weather"
| Sky |
Temp |
Humidity |
Water |
Forecast |
Enjoy sport? |
| Sunny |
Warm |
Normal |
Warm |
Same |
Yes |
| Sunny |
Warm |
High |
Warm |
Same |
Yes |
| Rainy |
Cold |
High |
Warm |
Change |
No |
| Sunny |
Warm |
High |
Cool |
Change |
Yes |
Problem 3. Learning the concept of "Japanese economy car"
| Origin |
Manufacturer |
Color |
Decade |
Type |
Example Type |
| Japan |
Honda |
Blue |
1980 |
Economy |
Positive |
| Japan |
Toyota |
Green |
1970 |
Sports |
Negative |
| Japan |
Toyota |
Blue |
1990 |
Economy |
Positive |
| USA |
Chrysler |
Red |
1980 |
Economy |
Negative |
| Japan |
Honda |
White |
1980 |
Economy |
Positive |
|
|
|
| Japan |
Toyota |
Green |
1980 |
Economy |
Positive |
| Japan |
Honda |
Red |
1990 |
Economy |
Negative |
Ukryte odpowiedzi
Za szarymi prostokątami ukryte są odpowiedzi. Klikamy w nie dopiero wtedy, kiedy samodzielnie zapiszemy poprawną naszym zdaniem odpowiedź. Odsłonięcie szarego prostokąta ma służyć weryfikacji już nabytej wiedzy lub własnego rozumowania, a nie uczeniu się.
Ćwiczenia na zajęciach
- Learning – a typical problem is inducing general functions from training examples.
- Concept learning: acquire definition of some category given a sample of its positive and negative training examples. Or: inferring a boolean-valued function from training examples of its input and output.
- Search of hypotheses space for the one which best fits the training examples.
- Dwa cele: opisywanie danych i predykcja.
- Indukcja to uogólnianie. Jak brzmi hipoteza uczenia indukcyjnego? (kiedy uda się predykcja?) Każda hipoteza dobrze aproksymująca funkcję docelową na dostatecznie dużym zbiorze przykładów uczących będzie również dobrze ją aproksymowała na innych nieznanych przypadkach. (uwaga: w tym punkcie występują dwa różne znaczenia słowa "hipoteza" – pierwsze to "założenie", drugie to "klasyfikator" = "model danych").
- Jakich dwóch symboli używamy jako "filtrów" – elementów składowych hipotez w przestrzeni wersji? ?, ∅
- Spójrz na Problem 2. Co oznacza hipoteza < ?, Cold, High, ?, ? > Dobra pogoda to taka, gdy Temp=Cold i Humidity=High. Każda inna pogoda nie jest dobra.
- Jak zapisać hipotezę najbardziej ogólną? same symbole "?"
- Jak zapisać hipotezę najbardziej szczegółową? same symbole "∅"
- Przyjmujemy oznaczenia:
x – przykład
X – zbiór wszystkich możliwych przykładów
D – zbiór przykładów uczących, D⊆X
H – cała przestrzeń hipotez
h – hipoteza z H, każda h: X → {0, 1}
c – funkcja boole’owska ("koncept"), c: X → {0, 1}
- Zapisz ogólny wzór na liczbę wszystkich możliwych przypadków, jakie mogą występować. Iloczyn po liczbie różnych wartości atrybutów.
- Wyobraź sobie, że mamy Problem 2+, w którym występuje jeszcze jeden atrybut dwuwartościowy, a "Sky" może przyjmować dodatkowo wartość "Cloudy". Ile wtedy mogłoby być wszystkich przypadków? (konkretna liczba). 3*2*2*2*2*2=96
- Ile jest syntaktycznie różnych hipotez? (podaj ogólny wzór). Iloczyn po (liczbie różnych wartości atrybutów+1+1) – bo dodajemy dwa specjalne symbole ?, ∅
- Ile jest syntaktycznie różnych hipotez dla Problem 2+ ? (konkretna liczba) 5120
- Ile jest semantycznie różnych hipotez? (podaj ogólny wzór). Ponieważ jedno ∅ jest równoznaczne z wieloma, więc liczba semantycznie różnych hipotez to 1+ iloczyn po (liczbie różnych wartości atrybutów+1)
- Ile jest semantycznie różnych hipotez dla Problem 2+ ? (konkretna liczba) 973
- Ile jest możliwych funkcji c, czyli ile wynosi |C| ? Liczba podzbiorów zbioru X (power set), czyli 2|X|
- Ile ona wynosi dla Problem 2+ ? (konkretna liczba) 296 ≈ 1028
- Ile możemy opisać hipotez przy użyciu naszego "języka"? (konkretna liczba) 973 ≈ 103
- Co powoduje taką dużą dysproporcję? ograniczenie języka hipotez: mamy bardzo, bardzo prostą reprezentację całej wiedzy (tylko jedna "krotka"), a także, dwie różne wartości na atrybucie dla dwóch przypadków pozytywnych powodują już wstawienie "?"
- Uporządkowanie hipotez od ogólnych do szczegółowych:
hj jest bardziej lub tak samo ogólna jak hk ⇔ dla każdego x∈X, hk(x)=1 → hj(x)=1.
mamy więc porządek częściowy (partial order) w H
- Narysuj (jako przestrzeń wersji) H i zaznacz h=c dla problemu AND: A1={0,1}, A2={0,1}, W={0,1}.
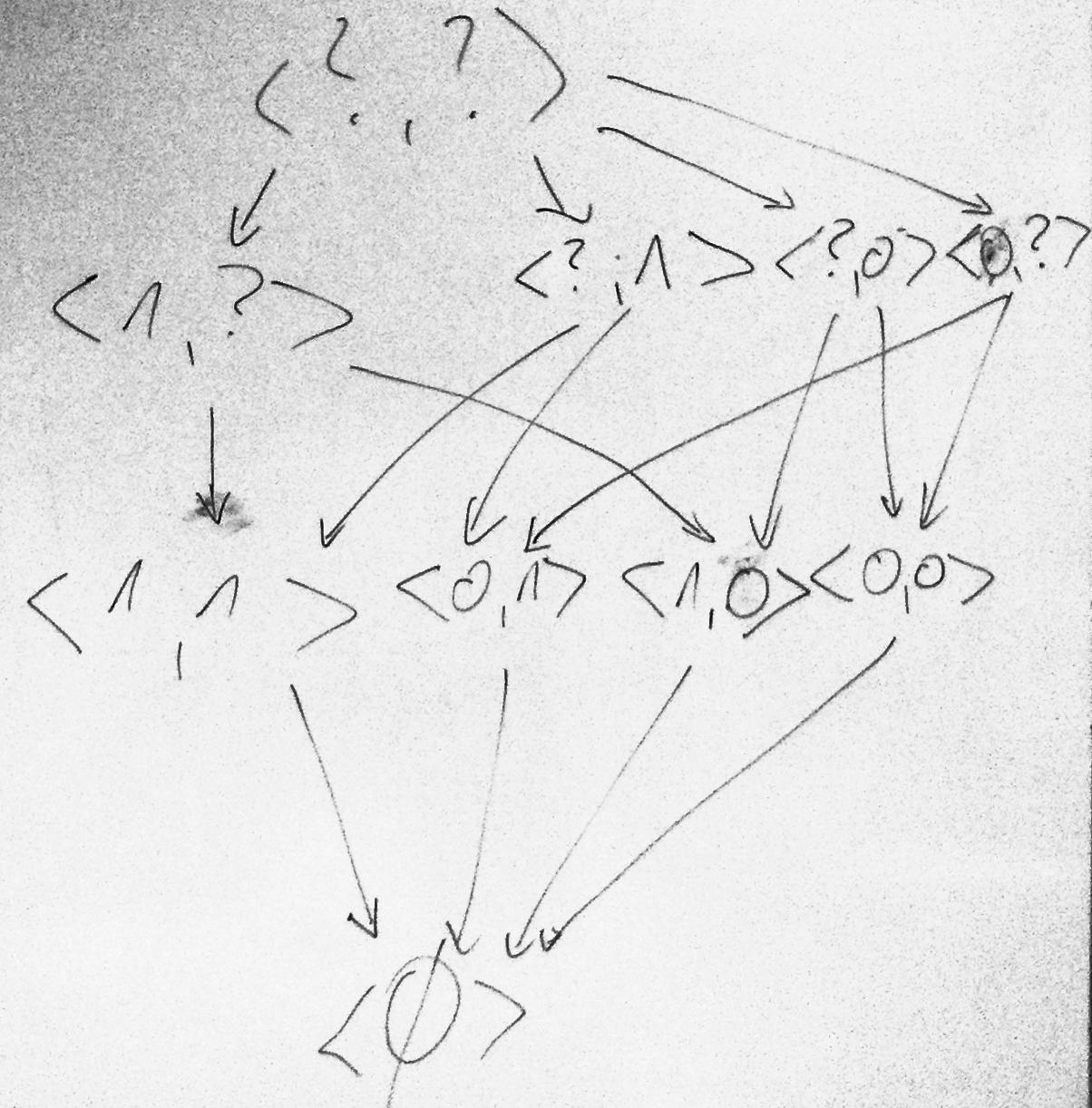
- ZADANIE DOMOWE: podaj C i C \ H.
- Dyskusja celu ML: pokrycie + bez żadnych −, pokrycie +, ominięcie −. Macierz pomyłek. Konsekwencje w różnych zastosowaniach – przykłady: leczenie, udzielanie kredytów, przyjmowanie do pracy, represyjność policji.
- Zaproponuj trzy algorytmy poszukiwania c w H. zapamiętywacz przypadków – rote learner (nie szuka w H!), list-then-eliminate, find-S, CEA, …
- Zastosuj find-S dla Problem 1
- Zastosuj find-S dla Problem 2
- Właściwości find-S: zawsze da na wyjściu h spójną z pozytywnymi przypadkami z D. Także z negatywnymi, jeśli c jest w H, i nie ma błędów w opisie D. Wady: czy odkryte h jest jedyne spójne z D, czy jest więcej takich? Czy najbardziej szczegółowa hipoteza jest najlepsza? Czy D jest spójny, czy ma błędy? – nie dowiemy się (negatywne przypadki są ignorowane). Nie dostajemy nawet alternatywnych, najbardziej specyficznych h, w przypadku kiedy jest ich wiele.
- Spełnianie a spójność:
x spełnia (satisfies)/jest pokrywany przez h jeśli h(x)=1, niezależnie od c(x).
h jest spójna/zgodna (consistent) z D iif h(x)=c(x) dla każdego <x, c(x)> z D.
Przestrzeń wersji VSH,D to podzbiór H hipotez spójnych z D.
- Jak działa algorytm list-then-eliminate? VS:=H, potem usuwaj h niespójne z kolejnymi x z X. Zwróci wszystkie h spójne z X, ale duża złożoność! (wielkość H)
- Ograniczenia H: G (ogólne/general) i S (szczegółowe/specific). G – podzbiór H najbardziej ogólnych hipotez. S – najmniej ogólnych. Wyznaczane przy użyciu relacji ogólności, spójności, i zbioru D.
- Wymień poszczególne kroki algorytmu CEA. Cecha tego algorytmu: w pewnych sytuacjach |G| może rosnąć wykładniczo od ilości przykładów.
- Wykonaj algorytm CEA dla Problem 1 (rysuj po każdym kroku VS).
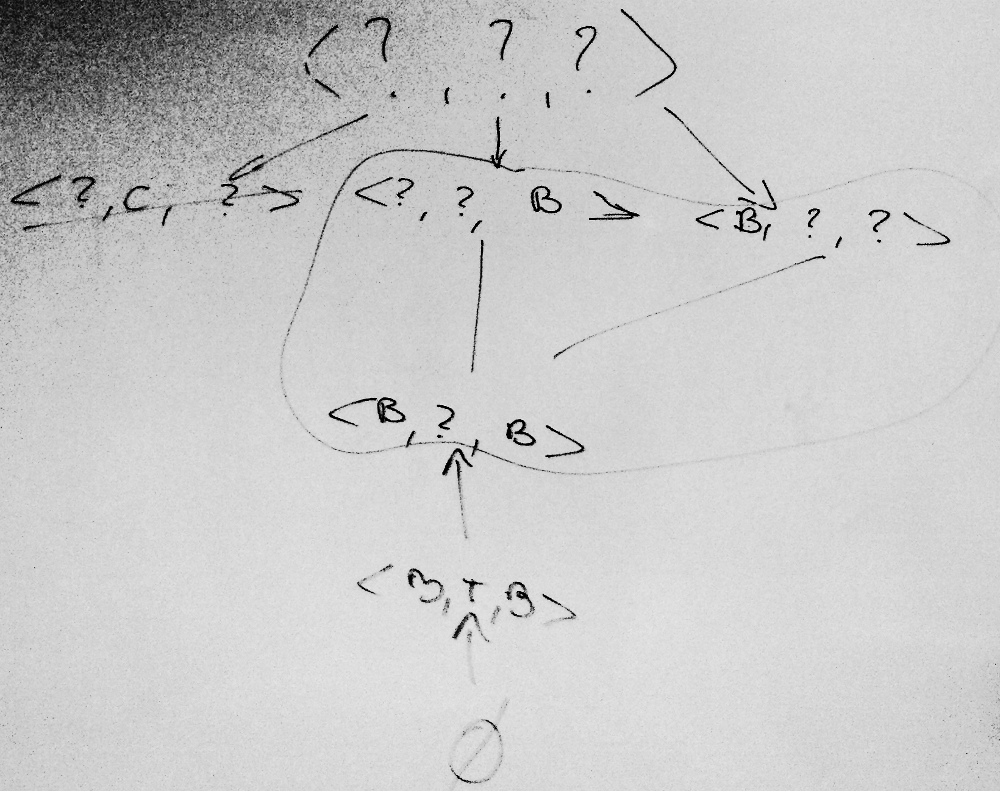
- Wykonaj algorytm CEA dla Problem 2 (narysuj ostatnie VS).
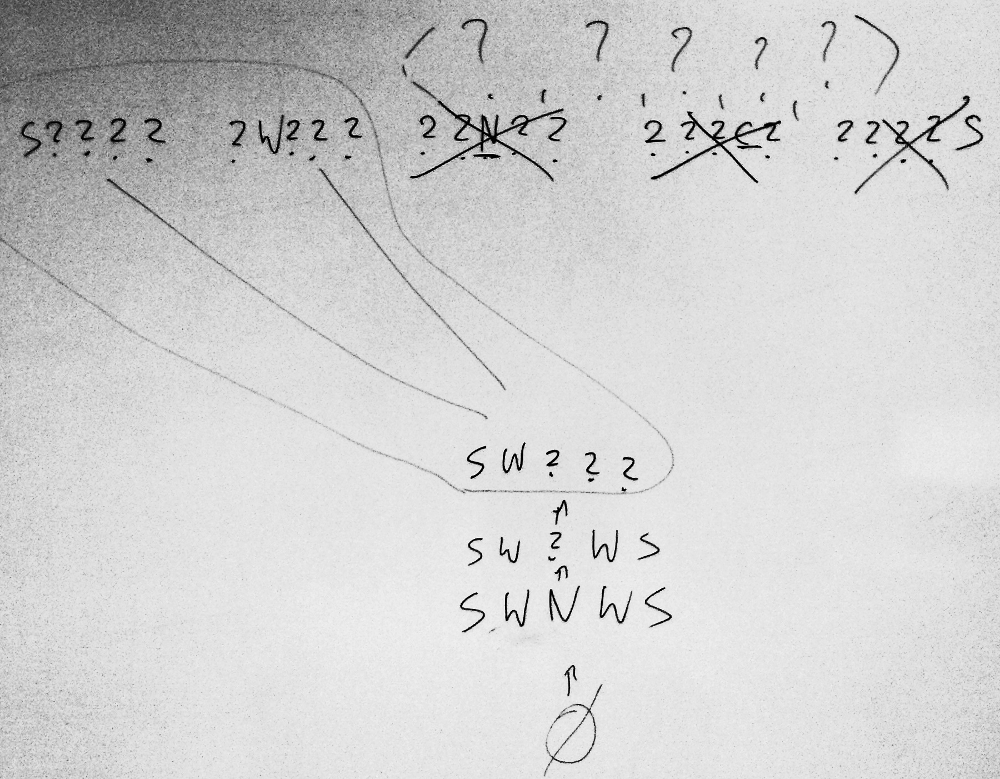
- Dokonaj klasyfikacji przykładowej sytuacji na podstawie hipotez opisujących nasze dane ("zbiór uczący"). Czy surfer uznałby ciepłą, słoneczną pogodę jako dobrą? A chłodną słoneczną?
- Własności CEA:
- Kiedy będzie zbieżny do poprawnego c? brak błędów w przypadkach uczących, istnienie c w H.
- Czy toleruje błędy w zbiorze uczącym? nie, jest bardzo wrażliwy na błędy (traktuje każdy przypadek tak samo – jako poprawny).
- Czy możemy wyrazić dysjunkcję? nie, ogranicza nas język hipotez.
- Jakie przypadki przyspieszają najbardziej uczenie? takie, które przez połowę h z VS są klasyfikowane dodatnio (x spełnia połowę z nich), a przez resztę ujemnie.
- Czy jeśli w VS mamy wiele hipotez, to daje nam to jakąś użyteczną informację przy próbie klasyfikacji nowego przykładu x? tak, można "głosować" nimi o spodziewanej przynależności x do c.
- Czy CEA może działać dla mniej ograniczonej reprezentacji? Czego wymaga do działania? może, wymaga tylko relacji "ogólniejsza niż" porządkującej hipotezy.
- Zauważ kompromis: prostota algorytmu (np. list-then-eliminate albo find-S) a jego wydajność i możliwości (CEA).
- Jakie jest znaczenie słowa bias? uprzedzenie, ukierunkowanie, obciążenie
- Przede wszystkim, uprzedzeniem przedstawionej tu przestrzeni wersji jest założenie, że c jest w H.
- Co stanowi kolejne największe ograniczenie przestrzeni wersji? prosty, ograniczony "język", czyli reprezentacja wiedzy. Nie można wyrazić (Sky=Sunny or Sky=Cloudy) gdy Sky=Rainy ma być negatywne.
- Skoro uboga reprezentacja jest ograniczeniem, to powiemy, że inductive bias is representational
- Gdybyśmy chcieli jakoś zlikwidować to ograniczenie (stworzyć unbiased learner), to co powinniśmy zrobić? dopuścić również dysjunkcje (→ algorytm AQ); można by wtedy opisać każde c.
- Jaka byłaby wtedy konsekwencja? Co byśmy otrzymywali dla różnych zbiorów danych? Zapamiętane wszystkie przypadki pozytywne, często brak uogólnienia (chyba, że byłoby bardzo mało lub wcale przypadków negatywnych).
- Zatem we wnioskowaniu indukcyjnym musi być jakieś uprzedzenie. Skoro nie reprezentacja by ograniczała, to co innego? Algorytm musiałby "nie chcieć" korzystać w pełni z możliwości reprezentacji – algorithmic inductive bias; jednym ze sposobów zniechęcenia algorytmu do nadużywania reprezentacji jest regularyzacja.
- Dla chętnych: wykonaj CEA dla Problem 3 (Last but one – no changes. The last one – VS collapses).
- Zapamiętaj: większość algorytmów uczenia maszynowego daje w wyniku działania tylko jedną, wybraną hipotezę (bo mają jakiś inductive bias) pomimo tego, że prawie zawsze istnieje bardzo wiele hipotez opisujących docelowe pojęcie!