Zastosowanie naiwnego klasyfikatora Bayes'a do klasyfikowania dokumentów tekstowych
Naiwny klasyfikator Bayes'a
Naiwny klasyfikator Bayes'a jest jedną z metod uczenia maszynowego, stosowaną do rozwiązywania problemu sortowania klas decyzyjnych. Zadaniem klasyfikatora Bayes'a jest przyporządkowanie nowego przypadku do jednej z klas, przy czym ich zbiór musi być skończony i zdefiniowany a priori.
Każdy przykład uczący opisany jest przy pomocy zbioru atrybutów warunkowych {Ai} i jednego atrybutu decyzyjnego D. W odróżnieniu od wielu innych technik uczenia maszynowego, tutaj nie zakłada się, że każdy przykład opisany jest przy pomocy takiego samego zbioru atrybutów warunkowych (z drugiej jednak strony, aby zachować spójność z innymi podejściami, można przyjąć interpretację, że zbiór atrybutów warunkowych jest stały dla wszystkich przykładów, natomiast poszczególne przykłady mogą zawierać wartości brakujące, które nie są brane pod uwagę zarówno podczas uczenia, jak i podczas klasyfikacji).
W myśl teorii Bayes'a, najbardziej prawdopodobną klasą, do której należy przypisać nowy obiekt, opisany wartościami n-atrybutów warunkowych Aj1 = vj1, Aj2 = vj2 … Ajn = vjn (lub w skrócie <vj1, vj2 … vjn>), jest klasa di, która maksymalizuje prawdopodobieństwo warunkowe P(di | vj1, vj2 … vjn). Klasa ta oznaczona jest jako dMAP (maximum a posterori).
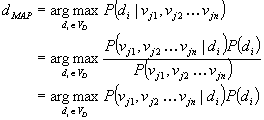 (1)
(1)
We wzorze (1) przez VD oznaczono dziedzinę atrybutu decyzyjnego (czyli zbiór klas decyzyjnych). W ostatniej linii (1) usunięto mianownik – prawdopodobieństwo P(vj1, vj2 … vjn) ma wartość stałą, niezależną od klasy decyzyjnej di, więc nie ma ono wpływu na wybór klasy dMAP.
Prawdopodobieństwo P(di) można oszacować w prosty sposób (i niezależnie od wielkości zbioru uczącego) jako stosunek liczby przykładów uczących należących do klasy di do liczby wszystkich przykładów uczących. Oszacowanie prawdopodobieństwa P(vj1, vj2 … vjn | di) w analogiczny sposób (tzn. jako stosunek liczby przykładów uczących opisanych wartościami atrybutów warunkowych <vj1, vj2 … vjn > i należących do klasy di do liczby wszystkich przykładów uczących z klasy di) jest dopuszczalne jedynie dla bardzo dużych zbiorów przykładów uczących.
Aby umożliwić łatwe oszacowanie prawdopodobieństwa P(vj1, vj2 … vjn | di), w naiwnym klasyfikatorze Bayes'a wprowadzono założenie o warunkowej niezależności wartości atrybutów przy ustalonej klasie decyzyjnej. Po przyjęciu takiego założenia, prawdopodobieństwo to można zapisać jako:
![]()
Natomiast prawdopodobieństwo P(vjk | di) można oszacować jako stosunek liczby przykładów uczących z klasy di, dla których wartość atrybutu Ajk równa jest vjk, do liczby wszystkich przykładów uczących z klasy di.
Po uwzględnieniu wspomnianego wyżej założenia, do klasyfikacji nowego przykładu wybrana zostaje klasa dNB (Naïve Bayes).
![]()
Warto tutaj zaznaczyć, że etap estymacji prawdopodobieństw odpowiada etapowi uczenia się (czyli etapowi budowy klasyfikatora, np. generowaniu drzew decyzyjnych lub indukcji reguł) w innych metodach uczenia maszynowego.
Oszacowywanie prawdopodobieństwa
Przy oszacowywaniu prawdopodobieństwa, np. P(vjk | di), może się okazać, że otrzymana estymata jest zbyt mała w porównaniu do rzeczywistego prawdopodobieństwa. Ma to miejsce szczególne wtedy, gdy licznik ułamka w estymacie jest bardzo mały (spośród n wszystkich przypadków, tylko n+ ma rozważaną wartość atrybutu vjk w klasie di). Aby rozwiązać ten problem wprowadzono m-estymatę prawdopodobieństwa:
![]()
w której p jest wstępną estymatą szacowanego prawdopodobieństwa, a m jest stałą zwaną rozmiarem równoważnej próbki (equivalent sample size). Taka nazwa stałej wynika z interpretacji, w której m-estymata potraktowana jest jako uzupełnienie zbioru uczącego m dodatkowymi przykładami.
W przypadku oszacowywania prawdopodobieństwa wystąpienia wartości atrybutu, jeżeli brak jest innych informacji, zazwyczaj przyjmuje się p równe 1/k, gdzie k jest liczbą możliwych wartości rozważanego atrybutu.
Szczególnym przypadkiem m-estymaty jest wykorzystywana w wielu zastosowaniach estymata Laplace'a (zob. np. tu albo tu (str. 18/20)).
Klasyfikacja dokumentów tekstowych
Naiwny klasyfikator Bayes'a jest jedną z najbardziej efektywnych metod uczenia maszynowego służącą do klasyfikacji dokumentów tekstowych. W praktyce stosowany jest najczęściej do filtrowania dokumentów (np. w przeszukiwarkach internetowych).
Każdy dokument tekstowy opisany jest przy pomocy zbioru atrybutów warunkowych {Ai}. Atrybut Ai oznacza i-tą pozycję słowa w dokumencie (np. przy założeniu, że ten akapit stanowi oddzielny dokument, atrybut A1 oznacza pierwszy wyraz w akapicie, a jego wartość wynosi 'każdy'). Należy zauważyć, że liczba atrybutów warunkowych (oznaczająca długością tekstu) może być zmienna.
Każdy przykład (dokument) uczący opisany jest również przy pomocy wartości atrybutu decyzyjnego. Zbiór klas decyzyjnych jest zależny od zastosowania – może on zawierać określenia tematyki, której poświęcone są teksty (np. komputery, samochody …) lub oceny tekstu (np. interesujący, nudny …).
Nowy dokument, zawierający n słów, z których pierwsze – A1 to wA1, drugie A2 = wA2, … ostatnie An = wAn, przyporządkowywany jest do klasy dNB, wyznaczonej jako:
![]()
Warto zauważyć, że w przypadku dokumentów tekstowych nie jest spełnione założenie o warunkowej niezależności wartości atrybutów warunkowych (słowa tworzą zwroty, w których na podstawie jednego słowa można przewidzieć następne – np. zwrot 'przede wszystkim'), jednak w praktyce nie obniża to zbytnio skuteczności klasyfikatora.
Ponieważ zbiór atrybutów warunkowych oraz zbiór możliwych wartości dla każdego z atrybutów (czyli zbiór możliwych słów) są zazwyczaj bardzo duże, oszacowanie prawdopodobieństw P(wAj | di) może być bardzo trudne, dlatego przyjęto upraszczające założenie, że prawdopodobieństwo wystąpienia słowa jest niezależne od jego pozycji w tekście, tzn. jeżeli wAi = wk i wAj = wk (gdzie wk oznacza k-te słowo w słowniku DICT, utworzonym ze słów występujących w tekstach uczących), to P(wAi | di) = P(wAj | di) = P(wk | di). Dzięki takiemu założeniu znacząco maleje liczba estymat prawdopodobieństwa, jakie trzeba wyznaczyć podczas uczenia.
Przy wyznaczaniu estymat P(wk | di) stosuje się następującą m-estymatę:
![]()
w której n oznacza całkowitą liczbę słów w tekstach uczących należących do klasy di, nk – liczbę wystąpień słowa wk w tekstach z klasy di, a |DICT| – rozmiar słownika, czyli liczbę rozróżnialnych słów występujących we wszystkich tekstach uczących.
Algorytm uczący i testujący przedstawione są poniżej. Warto zwrócić uwagę, że podczas klasyfikacji nie są pod uwagę słowa z klasyfikowanego dokumentu, które nie występują w słowniku DICT – klasyfikacja dokonywana jest jedynie na podstawie zbioru positions.
Algorytm uczący i testujący
LearnNaiveBayes(examples, VD)
examples – set of learning documents
VD – set of decision classes
begin
DICT
:= set of all distinct words occuring in any text document from examples
for
each di
in VD
do
begin
docsi := subset of documents from examples that belong to class di
P(di) := |docsi| / |examples|
texti
:= single document created by concatenating all members of docsi
n := total number of words in texti
for
each word wk in DICT do begin
nk
:= number of times word wk occurs in texti
P(wk
| di)
:= (nk + 1) / (n + |DICT|)
end
end
end
ClassifyNaiveBayes(doc)
doc – document to be classified
begin
positions := set of indexes (for each word in doc find its index in DICT)
return
dNB
end