In this section we give some examples of applying the divisible task method. First let us consider a numerical example.
Consider a computer system consisting of four identical PEs
connected by identical communication links.
Each PE has a network processor, and is capable of simultaneous computing
and communicating.
The amount of the returned results is constant and equal to 1024 bytes.
The order of data return is the order of activating PEs
(cf. Fig.4(b)).
We use equations (7) to find the distribution of the load.
From the solution one can compute the total
processing time, which is ![]() .
In the following table results of solving equations (7)
for
.
In the following table results of solving equations (7)
for ![]() bytes, are presented.
bytes, are presented.
| system A | system B | system C | |
| 0.0002324 | 0.000692 | 0.000596 | |
| 1E-11 | 1.25E-08 | 1.7485E-06 | |
| 1.08E-07 | 3.9E-05 | 0.0011377 | |
| processing time [s] | 581 | 1730 | 1497 |
In the above table parameters ![]() were not intended
to represent any particular computer system.
Still, system A may represent a shared memory
supercomputer from the 80-ties, system B is
a representative of massively parallel message passing computer
from the beginning of the 90-ties,
while system C is a cluster of contemporary (1997)
PC-compatible computers with Linux operating system and PVM.
The conclusion that can be derived from the above table is
that contemporary PCs are as good as leading computers 6-7 years ago.
Thus, time beats any machine.
were not intended
to represent any particular computer system.
Still, system A may represent a shared memory
supercomputer from the 80-ties, system B is
a representative of massively parallel message passing computer
from the beginning of the 90-ties,
while system C is a cluster of contemporary (1997)
PC-compatible computers with Linux operating system and PVM.
The conclusion that can be derived from the above table is
that contemporary PCs are as good as leading computers 6-7 years ago.
Thus, time beats any machine.
As we are able to compute the processing time for the whole
load both on a single machine, and on the given number of PEs,
we are also able to compute speedup, utilization etc.
for the considered computer system and communication algorithm.
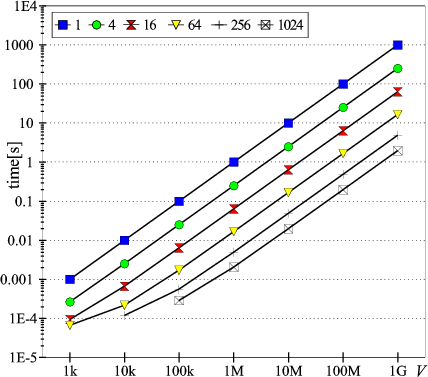
In the following example we will analyze a 3-dimensional mesh
with PEs using 1 port at a time (![]() ) and circuit switched routing.
Since speedup can be an ambiguous performance measure,
we will concentrate on the processing time.
In Figs.6 and 7 we present
a relation between the processing time and the volume of work
) and circuit switched routing.
Since speedup can be an ambiguous performance measure,
we will concentrate on the processing time.
In Figs.6 and 7 we present
a relation between the processing time and the volume of work ![]() for 1-, 4-, 16-, 64-, 256-, 1024-processor systems.
In both figures the communication parameters
are
for 1-, 4-, 16-, 64-, 256-, 1024-processor systems.
In both figures the communication parameters
are
![]() , and
, and ![]() .
In Fig.6 processors have
.
In Fig.6 processors have
![]() ,
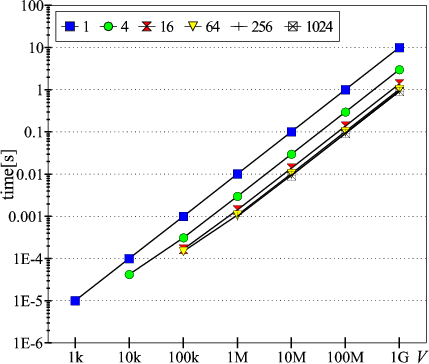
and in Fig.7 processing rate is better and equal to
,
and in Fig.7 processing rate is better and equal to
![]() .
.
 |
 |