Distribution of the load can be found in O(m) time from the equations
![]()
M.Drozdowski, P.Wolniewicz
Institute of Computing Science, Poznań University of Technology
PLAN OF THE PRESENTATION
1. INTRODUCTION
2. PROCESSING DIVISIBLE JOBS ON STAR AND BUS TOPOLOGIES
3. EXPERIMENTAL APPLICATIONS
4. RESULTS
5. DISCUSSION
6. CONCLUSIONS
1. INTRODUCTION
DIVISIBLE JOB - is a task (a computation, a program) which can be divided into parts of arbitrary sizes which can be processed independently on different processors.
In other words:
·
granularity of parallelism ¾ is fine,·
there are no data dependencies (precedence constraints).
EXAMPLES OF DIVISIBLE JOBS
- distributed search for a record in a database
- searching for a pattern in a text/audio/graphical file
- processing big measurement data files
- molecular dynamics simulations
- some problems of linear algebra
- some methods of solving partial differential equations
- parallel metaheuristics
DATA DISTRIBUTION AND COMPUTATION PROCESSES
-
Initially all the load V to be processed resides on one processing element (PE) called ORIGINATOR.- Originator intercepts some part a 0 of the data for local processing, and sends the rest V-a 0 to its neighbors for remote processing.
- Processing element i intercepts part a i of the received data and sends the rest to its still idle neighbors.
- This process is repeated until all the PEs (processing elements) are activated.
- After completion of the computations the results may be returned to the originator.
Since data distribution takes place over a relatively slow network communication delays constitute important part of the total processing time.
We have to distribute the load (work, data) among the processors such that total data communication and computation time is the shortest.
Divisible job model has been successfully applied to analyze distributed computations in chains (linear arrays), stars, trees, buses, meshes, hypercubes, multistage interconnections of processing elements.
Here we concentrate on star/bus interconnection.
The goal is to confirm viability of divisible job model in practice.
2. PROCESSING DIVISIBLE JOBS ON STAR AND BUS TOPOLOGIES
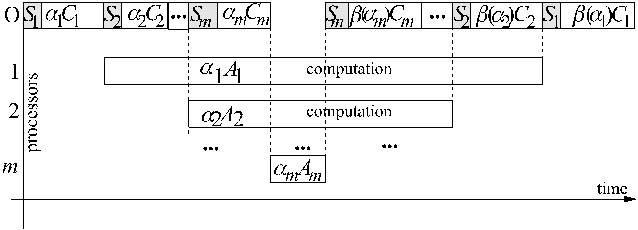
Assume:
- originator communicates but does not computes
- communication delay for message of size x is on link j Sj
+ Cj x- computation of amount x of work lasts on PE j Aj x
- amount of work sent to processing element j a j
- amount returned results for x units of input data b (x)
- results are returned to the originator in the inverted order of sending data
Communications and computations (Gantt) chart
Distribution of the load can be found in O(m) time from the equations
![]()
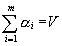
The above set of equations can be solved in O(m) time
(provided a feasible solution exists).
This way of returning results will be called LIFO case.
Assume:
- originator communicates but does not computes
- communication delay for message of size x is on link j Sj + Cj x
- computation of amount x of work lasts on PE j Aj x
- amount of work sent to processing element j aj
- amount returned results for x units of input data b (x)
- results are returned to the originator in the order of sending data
Communications and computations (Gantt) chart
The distribution of the load can be found from equation set:
![]() for i=1,...,m-1
for i=1,...,m-1
The above set of equations can be solved in O(m) time (provided a feasible solution exists).
This way of returning results will be called FIFO case.
3. EXPERIMENTAL APPLICATIONS
SEARCH FOR A PATTERN
Verify if string S contains substring x.
Originator sends x and aj characters from string S to PE j.
Each of the PEs returns positions at which the substring x starts.
The amount of results is very small compared to V, typical of a search in a database.
V=
strlen(S); b
(x)@0.005x.
COMPRESSION
Compress string S.
Originator sends a
j units of data to PE j for remote compression.
Each of the PEs uses LZW algorithm to compresses the data and later returns the results.
Originator appends the results to the packed output file.
V=strlen(S); b
(x)@
(0.55±0.05)x.
JOIN
Execute join on databases A and B.
COLORING AND GENETIC SEARCH
Find minimum number of colors properly coloring nodes of graph G.
4. RESULTS
PLATFORMS vs. APPLICATIONS
|
applications (year) platform |
search for |
compression |
join |
coloring and |
|
A: (1995) various Sun workstations: SLC, IPX, SparcClassic, PVM |
· |
|||
|
B: (1997) various PCs: 486DX66, RAM 8M - P166, RAM 64M, Linux, PVM |
· |
|||
|
C: (1997) IBM SP2, PVM |
· |
|||
|
D: (1999) homogeneous PCs: P-133, RAM 64M, WinNT, MPI |
· |
· |
· |
|
|
E: (1999) various PCs:P-100, RAM 24M - Celeron-330, RAM 64M, Win98, Java |
· |
|||
|
F: (1999) homogeneous PCs: P-200MMX, RAM 32M, Linux, Java |
· |
SCHEME OF EXPERIMENTS
The goal: apply divisible job model in practice and verify its correctness.
The verification was done by comparing the real and the predicted execution times of some application when data is distributed in chunks of sizes (a j) calculated according to the divisible job model.
To formulate the above equation sets we had to measure parameters
Aj, Cj, Sj for j=1, ,m, and b (x).
Communication Cj, Sj parameters were measured by a ping-pong test.
The time of the communications and the amounts of data were stored. After collecting a number of such pairs, parameters Cj, Sj were calculated using linear regression.
Processing rates Aj were measured as an average of the ratios of the computation time and the size of data processed.
b (x) depends on the application, and the way of obtaining it and has been explained in the previous section.
TYPICAL VALUES OF COMMUNICATION PARAMETERS
|
(year) platform |
C j [m s/B] |
S j [m s] |
|
A: (1995) various Sun workstations: SLC, IPX, SparcClassic, PVM |
70.7± 0.3 |
636000± 86000 |
|
B: (1997) various PCs: 486DX66, RAM 8M - P166, RAM 64M, Linux, PVM |
7031± 13 |
3000± 9000 |
|
C: (1997) IBM SP2, PVM |
68.6± 0.1 |
205± 144 |
|
D: (1999) homogeneous PCs: P-133, RAM 64M, WinNT, MPI |
1.04± 0.13 |
6200± 7200 |
|
E: (1999) various PCs:P-100, RAM 24M - Celeron-330, RAM 64M, Win98, Java |
111± 4 |
120000± 10000 |
|
F: (1999) homogeneous PCs: P-200MMX, RAM 32M, Linux, Java |
6± 240 |
8770± 240 |
|
(1999) homogeneous PCs: P-200MMX, RAM 32M, Linux, PVM |
18.3± 0.2 |
11000± 25000 |
|
(1999) homogeneous PCs: P-200MMX, RAM 32M, WinNT, PVM |
15.9± 0.3 |
248000± 35000 |
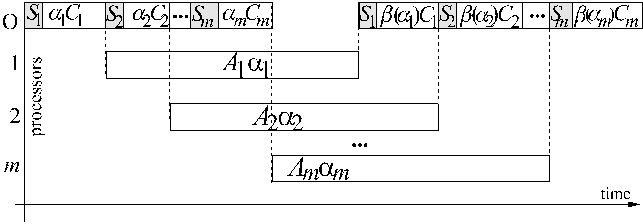
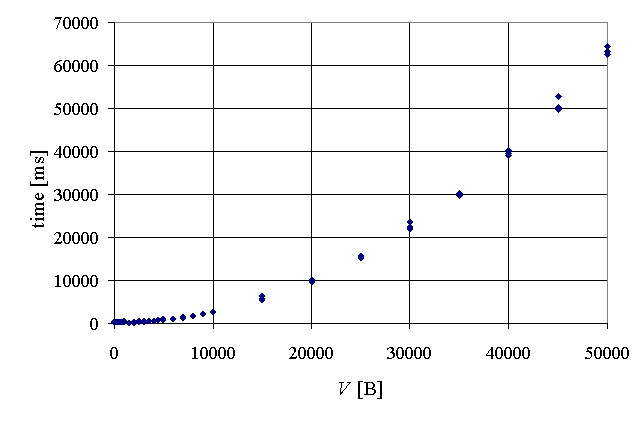
Communication time vs. size of the message IBM-SP2
Communication time vs. size of the message PC486, 8MRAM, Linux
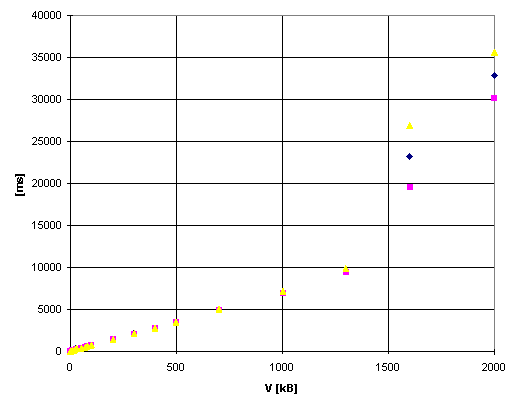
Communication time vs. size of the message PC Win95, Java
EXAMPLE VALUES OF PROCESSING RATES
|
(year) platform |
application |
Aj [m s/B] |
|
A: (1995) Sun SLC, PVM |
search for a pattern |
6.99± 0.03 |
|
B: (1997) PC: 486DX66, RAM 8M, Linux, PVM |
compression |
1500± 20 |
|
C: (1997) IBM SP2, PVM |
compression |
650± 60 |
|
D: (1999) homogeneous PCs: P-133, RAM 64M, WinNT, MPI |
search for a pattern |
0.838± 0.007 |
|
D: (1999) homogeneous PCs: P-133, RAM 64M, WinNT, MPI |
join |
1176± 6 |
|
E: (1999) Celeron-330, RAM 64M, Win98, Java |
coloring and genetic search |
25± 76 |
|
F: (1999) homogeneous PCs: P-200MMX, RAM 32M, Linux, Java |
coloring and genetic search |
26± 2 |
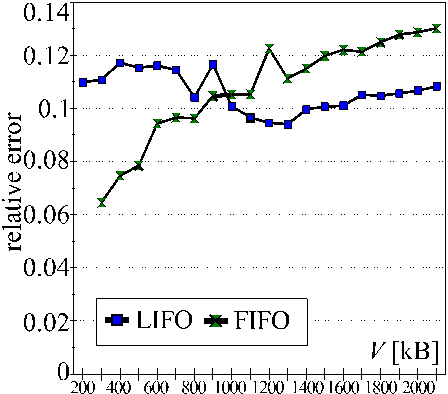
ACCURACY OF THE MODEL
Relative difference between the model and reality in "search for a pattern" application on platform D (PCs, WinNT, MPI).
Relative difference between the model and reality in "compression" application on platform C (IBM-SP2, PVM).
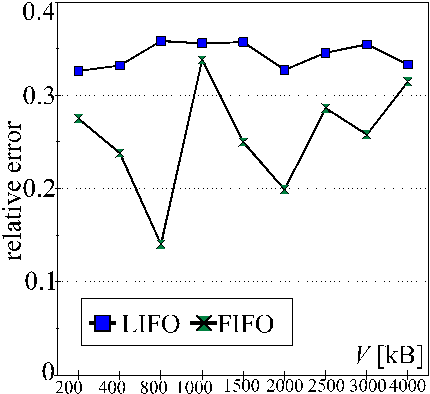
Relative difference between the model and reality in "join" application on platform D (PCs, WinNT, MPI).
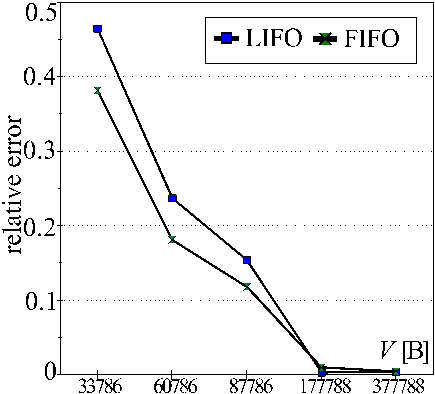
Relative difference between the model and reality in "coloring" application on platform F (PCs, Linux, Java).
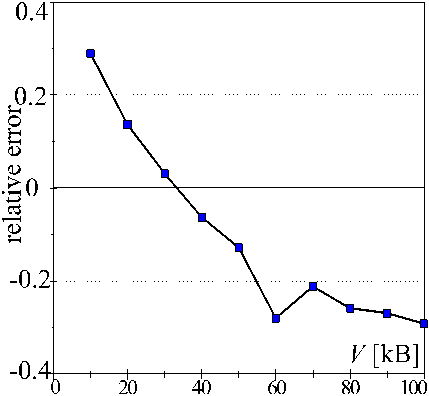
5. DISCUSSION
ON THE CORRECTNESS OF THE MODEL
- There are platforms and applications where the model is accurate (error 10% and less: "compression" on platform C, "join" on platform D, also "search for a pattern" in Transputer system [other publication]).
- There are also platforms where the predictions are not so accurate (error 30-40%)
ON THE SOURCES OF INACCURACY
- "Errors R us"- errors in setting up the experiment, e.g.:
- measuring duration of different activities while establishing Aj, Cj, Sj than the set of activities performed in the application.
- misunderstanding or lack of knowledge about interactions in the system.
- Calling operating system services introduce indeterminism:
- memory allocation,
- disk references also in the case of buffers for long messages.
- Nonlinear dependence of communication or processing times on the volume of data
- Network access method, and software running in parallel with our applications influence Aj, Cj, Sj, this influence should diminish with growing value of V in stable state systems.
- Standard deviation of Aj, Cj, Sj, is an estimate of the influence of these statistical phenomena on the model.
Aj, Cj, in most of the cases have deviation @ 0.01
Sj has deviation even as much as 3.3!
6. CONCLUSIONS
Results of applying divisible job model in practice have been presented.
Applicability of the model in real life has been demonstrated, on the one hand.
On the other hand there are also cases where the model is not so accurate. These cases need further experimental verification.
Some sources of divergence of the model and reality have been pointed out. Their quantitative influence need further analysis.
The results obtained may lead to a refinement of the model.