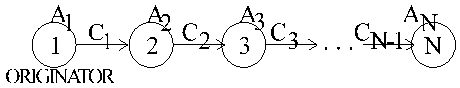
Scheduling a divisible job in a transputer system
J. B
łażewicz, M. Drozdowski, M. MarkiewiczInstitute of Computing Science,
Pozna
ń University of TechnologyPozna
ń, Poland
PLAN OF THE PRESENTATION
1. INTRODUCTION
- FORMULATION OF THE PROBLEM
- PREVIOUS RESULTS
2. MODEL FOR THE TESTBED
3. RESULTS OF THE EXPERIMENTS
4. CONCLUSIONS
1. INTRODUCTION
DIVISIBLE JOB
- is a task (a computation, a program) which can be divided into parts of arbitrary sizes. These parts can be processed independently of each other on different processors.In other words:
· granularity of parallelism - is fine,
· there are no data dependencies (precedence constraints).
EXAMPLES
- distributed searching for a record in a database,
- searching for a pattern in a text, audio, graphical file,
- processing big measurement data files
- molecular dynamics simulations,
- some problems of linear algebra,
- some methods of solving partial differential equations
- parallel metaheuristics
DESCRIPTION OF DATA DISTRIBUTION
AND COMPUTATION PROCESSES
-
Initially all the load to process resides on one processing element (PE) called ORIGINATOR.-
Originator intercepts some part of the data for local processing, and sends the rest to its neighbors for remote processing.-
Each processor intercepts some part of the received data and sends the rest to its still idle neighbors-
This process is repeated until all the processors are activated-
After completion of the computation the results may be returned to the originator
Since data distribution takes place over a (relatively) slow network COMMUNICATION DELAYS constitute important part of the total processing time.
Our GOAL is to find division of the load (data) among the processors such that the whole data distribution and computation time is minimal possible.
PREVIOUS RESULTS
CHAIN
notation
N - number of processors,
Ai - processing rate
e.g. in seconds per byteCi
- communication rate e.g. in seconds per byteSi
- communication startup time e.g. in secondsV
- whole data volume (load) e.g. in bytesa i - the unknown part of the whole volume V to be processed by processor i, e.g. in bytes tu daæ folie z POC96
2. MODEL FOR THE TESTBED
The experiments were conducted in a T805 Transputer network with wormhole routing.
The test application was distributed searching for a string in a text file.
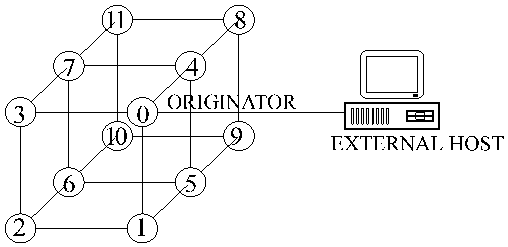
Initially, we assumed a logical STAR interconnection (3 PEs).
The distribution of the load can be found from equation set:
![]() for i=1,...,m-1
for i=1,...,m-1
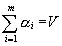
The above set of equations can be solved in O(m) time.
We extended the experiment to 8 PEs.
In this case the communication network was no longer equivalent to a star because PEs both route messages and compute. The real scattering graph is a tree resulting from the routing table.
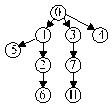 ®
6,2,5,1,11,7,3,4
®
6,2,5,1,11,7,3,4
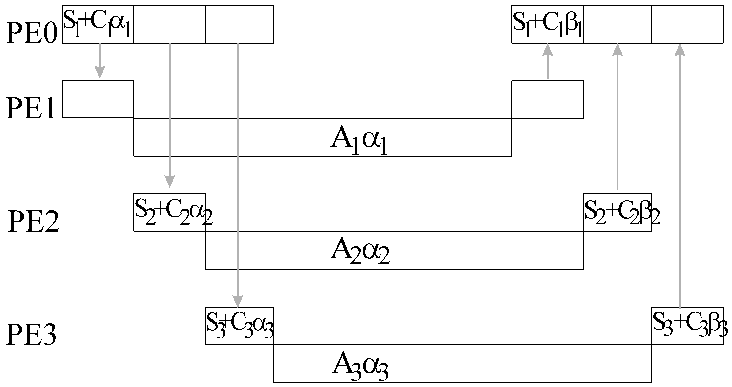
The communication-computation diagram is as follows
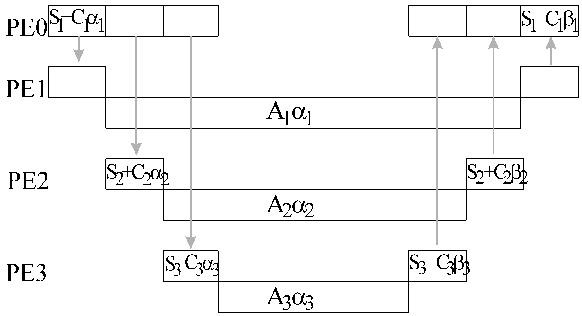
The distribution of the load can be found in O(m) time from the equations
![]()
3. RESULTS OF THE EXPERIMENTS
· Parameters Ai (processing time per data unit)
were measured as an average processing time per data unit in 100 execution times for searching in 300kB file.
· Parameters Ci, Si (transmission rate, startup),
were calculated as parameters of linear regression for a set of measurement pairs: transmission time t - for data volume v.
There were 100 data 'points'. Each point is an average of 3 repetitions.
· Results for the star model (each point is an average of 100 tries)
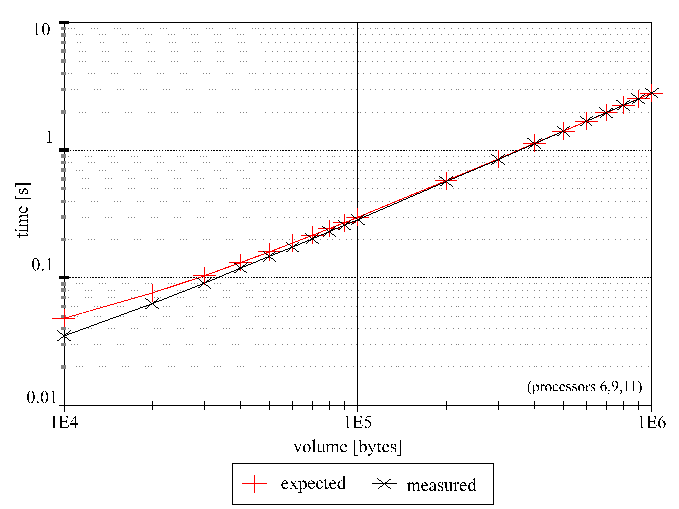
Deviation of the results from the expectation
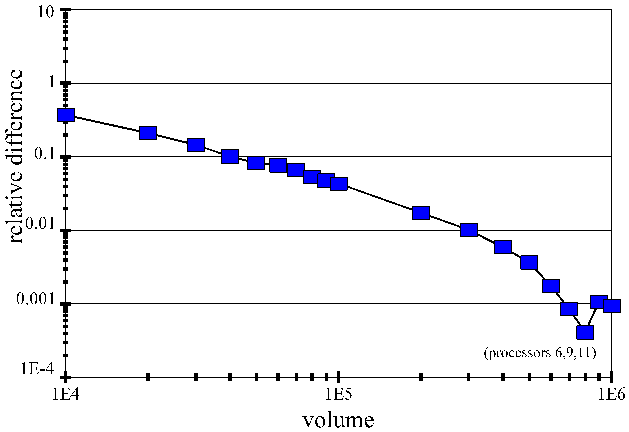
· Results for the tree model (the 2nd case)
Deviation of the results from the expectation
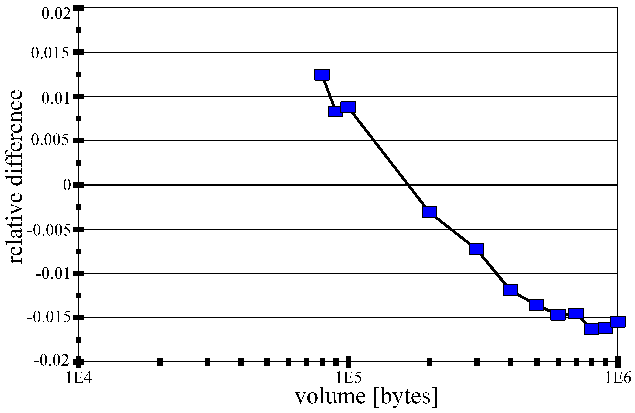
4. CONCLUSIONS
-
- the distribution of the work can be found deterministically basing on simple parameters like processor and communication speed
- the idea of divisible job provides a method of computer system performance evaluation
- preliminary experimental results confirm viability of the method
- further research:
- further verifications
- nonlinear processing/communication time dependence
- on-line algorithms
- other architectures