Laboratorium Przetwarzania Rozproszonego¶
Spis treści
- Laboratorium Przetwarzania Rozproszonego
- Parallel Virtual Machine (PVM)
- Przygotowanie środowiska pracy w systemach operacyjnych GNU/Linux
- Konsola systemu PVM
- Pierwszy program
- Schemat kompilacji programów systemu PVM
- Dynamiczne uruchamianie programów
- Przykład podstawowej komunikacji pomiędzy procesami
- Przykład komunikacji grupowej
- Realizacja topologii pierścienia
- Realizacja topologii pierścienia w pojedynczym programie
- Message Passing Interface (MPI)
- Algorytmy rozproszonego wzajemnego wykluczania
- Zaliczenie
- Parallel Virtual Machine (PVM)
Parallel Virtual Machine (PVM)¶
Przydatne zasoby internetowe dotyczące systemu PVM:
- strona domowa projektu;
- podręcznik użytkownika;
- często zadawane pytania (FAQ);
- opracowanie D. Wawrzyniaka.
Przygotowanie środowiska pracy w systemach operacyjnych GNU/Linux¶
- Logowanie SSH bez potrzeby podawania haseł:
$ ssh-keygen
$ ssh-copy-id -i ~/.ssh/id_rsa.pub login@hostname
$ ssh login@hostname
- Zmienne środowiskowe (warto zapisać ustawienia tych zmiennych w pliku ~/.bashrc):
$ export PVM_ROOT=/usr/lib/pvm3/
$ export PVM_SRC=$HOME/pvm3/src/
$ export PATH=$PATH:$PVM_ROOT/bin:$PVM_ROOT/lib
$ export PVM_ARCH=`pvmgetarch`
$ export PVM_HOME=$HOME/pvm3/bin/$PVM_ARCH
$ export PATH=$PATH:$PVM_HOME
$ export PVM_RSH=/usr/bin/ssh
- Katalogi systemu PVM:
$ cd ~
$ mkdir pvm3 ; mkdir pvm3/src ; mkdir pvm3/bin ; mkdir pvm3/bin/$PVM_ARCH
Uwaga
Na komputerach laboratoryjnych powinno być dostępne polecenie:
$ SETUP PVM
konfigurujące środowisko pracy systemu PVM.
Konsola systemu PVM¶
Konsolę systemu PVM uruchamia się poleceniem pvm (włączenie konsoli systemu uruchamia jednocześnie proces pvmd, jeśli nie był on wcześniej uruchomiony). Podstawowe polecenia konsoli PVM:
- help – uzyskanie pomocy na temat dostępnych poleceń;
- conf – wyświetlenie informacji o konfiguracji maszyny wirtualnej PVM;
- add – dodanie komputera do maszyny wirtualnej PVM, np.:
$ pvm
pvm> add hostname
- delete – usunięcie komputera z maszyny wirtualnej PVM;
- quit – opuszczenie konsoli (proces pvmd nie jest jednak zatrzymywany);
- halt – opuszczenie konsoli i zatrzymanie procesu pvmd;
- spawn – uruchomienie procesów w maszynie wirtualnej PVM;
- ps – wyświetlenie wszystkich zadań w maszynie wirtualnej PVM.
Ostrzeżenie
Po zakończeniu pracy w systemie PVM należy zatrzymać proces pvmd wydając w konsoli PVM polecenie halt .
W przeciwnym wypadku, w katalogu /tmp pozostanie plik o nazwie pvmd.[UID], który będzie uniemożliwiał ponowne uruchomienie systemu PVM, np. po restarcie komputera. W takiej sytuacji należy taki plik usunąć przed uruchomieniem procesu pvmd.
Pierwszy program¶
Pierwszy program “Hello World!”:
1 2 3 4 5 6 7 8 9 | #include <stdio.h>
#include "pvm3.h"
int main(int argc, char **argv) {
int mytid = pvm_mytid();
printf("%d: Hello World!\n", mytid);
pvm_exit();
return 0;
}
|
Zastosowane funkcje systemu PVM:
- int pvm_mytid()
- Funkcja w wyniku przekazuje unikalny, w ramach maszyny wirtualnej PVM, identyfikator tid procesu, który ją wywołuje.
- int pvm_exit()
- Wykonanie tej funkcji sygnalizuje, że wywołujący ją proces opuszcza maszynę wirtualną PVM. Funkcja przekazuje w wyniku status zakończenia procesu (wartości mniejsze od zera oznaczają błąd).
Schemat kompilacji programów systemu PVM¶
Schemat kompilacji programów systemu PVM w systemie operacyjnym GNU/Linux jest następujący:
$ gcc [NAZWA].c -o $PVM_HOME/[NAZWA] -L$PVM_ROOT/lib/$PVM_ARCH/ -I$PVM_ROOT/include/ -lpvm3 -lgpvm3
(Biblioteka gpvm3 zawiera funkcje systemu PVM obsługujące komunikację grupową).
Po skompilowaniu program może być uruchomiony w maszynie wirtualnej PVM z użyciem polecenia spawn konsoli systemu:
$ pvm
pvm> spawn [NAZWA]
Uwaga
Wynik działania tak uruchomionego programu zapisywany jest w pliku pvml.[UID] w katalogu /tmp.
Aby przekierować standardowe wyjście programu do konsoli systemu PVM należy uruchomić program w następujący sposób:
$ pvm
pvm> spawn -> [NAZWA]
Uruchomienie N kopii programu wymaga natomiast następującego polecenia:
$ pvm
pvm> spawn -N -> [NAZWA]
Programy systemu PVM mogą być także uruchamiane poza jego konsolą, jeśli proces pvmd został wcześniej uruchomiony (np. poleceniem pvm).
Dynamiczne uruchamianie programów¶
Przykład programu typu “master”, który uruchomia procesy typu “slave”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include <stdio.h>
#include "pvm3.h"
#define NPROC 5
int main(int argc, char **argv) {
int i;
int mytid = pvm_mytid();
int tids[NPROC];
int nproc = pvm_spawn("slave", NULL, PvmTaskDefault, 0, NPROC, tids);
printf("(MASTER) %d processes created: ", nproc);
for (i=0; i<NPROC; i++)
printf("%d ", tids[i]);
printf("\n");
pvm_exit();
return 0;
}
|
Kod programu typu “slave”, który zostanie uruchomiony przez program “master” (nazwa skompilowanego programu powinna odpowiadać pierwszemu argumentowi wywołania funkcji pvm_spawn() w kodzie programu typu “master”):
1 2 3 4 5 6 7 8 9 | #include <stdio.h>
#include "pvm3.h"
int main(int argc, char **argv) {
int mytid = pvm_mytid();
printf("(SLAVE) My tid = %d\n", mytid);
pvm_exit();
return 0;
}
|
Nowe funkcje systemu PVM zastosowane w przykładzie:
- int pvm_spawn(char *task, char **argv, int flag, char *where, int ntask, int *tids)
- Funkcja uruchamia ntask kopii programu o nazwie task i rejestruje je w maszynie wirtualnej PVM; parametr argv jest wskaźnikiem do tablicy zawierającej argumenty wywołania programów task; parametr where pozwala określić konkretny węzeł maszyny wirtualnej lub konkretną architekturę węzła, na którym mają zostać uruchomione tworzone programy – możliwe jest także pozostawienie wyboru węzła systemowi PVM; parametr flag pozwala określić dodatkowe opcje uruchamiania programów, a identyfikatory tid tworzonych procesów zapisane są w tablicy pod adresem określanym przez parametr tids. Funkcja przekazuje w wyniku liczbę faktycznie utworzonych procesów.
Przykład podstawowej komunikacji pomiędzy procesami¶
Przykład programu typu “master”, który wysyła komunikaty do procesów typu “slave”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <stdio.h>
#include "pvm3.h"
#define NPROC 5
#define MSGTAG 1234
int main(int argc, char **argv) {
int i;
int mytid = pvm_mytid();
int tids[NPROC];
int nproc = pvm_spawn("slave", NULL, PvmTaskDefault, 0, NPROC, tids);
printf("(MASTER) %d processes created\n", nproc);
for (i=0; i<NPROC; i++) {
pvm_initsend(PvmDataDefault);
pvm_pkint(&mytid, 1, 1);
pvm_pkint(&i, 1, 1);
printf("(MASTER) Sending message to process: no = %d, tid = %d\n", i, tids[i]);
pvm_send(tids[i], MSGTAG);
}
pvm_exit();
return 0;
}
|
Program typu “slave”, który odbiera komunikaty:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h>
#include "pvm3.h"
#define MSGTAG 1234
int main(int argc, char **argv) {
int tid, val;
int mytid = pvm_mytid();
int recv = pvm_recv(-1, MSGTAG);
pvm_upkint(&tid, 1, 1);
pvm_upkint(&val, 1, 1);
printf("(SLAVE: %d) Message received from: tid = %d, value = %d\n", mytid, tid, val);
pvm_exit();
return 0;
}
|
Nowe funkcje systemu PVM zastosowane w przykładzie:
- int pvm_initsend(int encoding)
- Funkcja ta czyści domyślny bufor nadawczy systemu i pozwala określić sposób kodowania i dekodowania komunikatów dla tego bufora – domyślnie stosowane jest kodowanie XDR (ang. eXternal Data Representation). W wyniku przekazywany jest identyfikator bufora komunikacyjnego.
- int pvm_pkint(int *ip, int nitem, int stride)
- Funkcja umieszcza w aktywnym buforze nadawczym tablicę typu int dostępną pod adresem *ip; liczba pozycji z tablicy *ip, które zostaną skopiowane do bufora jest określana parametrem nitem, a parametr stride wskazuje co którą wartość z tablicy należy kopiować.
- int pvm_send(int tid, int msgtag)
- Funkcja dodaje do danych w aktywnym buforze nadawczym etykietę numeryczną msgtag i wysyła je do zadania o identyfikatorze tid. W wyniku przekazywany jest status wykonania operacji wysłania danych.
- int pvm_recv(int tid, int msgtag)
- Funkcja wykonuje blokujący odbiór komunikatu – możliwe jest filtrowanie wiadomości według identyfikatorów nadawców, parametr tid, lub etykiet numerycznych, parametr msgtag. Wartość -1 tych parametrów oznacza wszystkie wartości. Odebrany komunikat znajduje się w nowoutworzonym buforze buforze odbiorczym, a poprzedni bufor odbiorczy jest zwalniany. Funkcja w wyniku przekazuje identyfikator nowego aktywnego bufora odbiorczego.
- int pvm_upkint(int *ip, int nitem, int stride)
- Funkcja pobierająca wartości z odebranego komunikatu – analogicznie do funkcji pvm_pkint().
Przykład komunikacji grupowej¶
Przykład programu typu “master”, który wysyła komunikat rozgłoszeniowy do grupy procesów:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #include <stdio.h>
#include <pvm3.h>
#define NPROC 4
#define MSG_MASTER 1
#define MSG_SLAVE 2
#define GROUPNAME "mygroup"
int main(int argc, char **argv) {
int tid = pvm_mytid();
int tids[NPROC];
int i, res = 0;
pvm_spawn("slave", NULL, PvmTaskDefault, 0, NPROC, tids);
pvm_joingroup(GROUPNAME);
pvm_barrier(GROUPNAME, 5);
pvm_initsend(PvmDataRaw);
pvm_pkint(&tid, 1, 1);
pvm_bcast(GROUPNAME, MSG_MASTER);
printf("(MASTER) Broadcast message sent\n");
for (i=0; i<NPROC; i++) {
pvm_recv(-1, MSG_SLAVE);
pvm_upkint(&res, 1, 1);
printf("(MASTER) Message received: no = %d, tid = %d\n", i, res);
}
printf("(MASTER) All messages received\n");
pvm_lvgroup(GROUPNAME);
pvm_exit();
return 0;
}
|
Program typu “slave”, który odbiera komunikat rozgłoszeniowy oraz przesyła wiadomość do procesu typu “master”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #include <stdio.h>
#include "pvm3.h"
#define MSG_MASTER 1
#define MSG_SLAVE 2
#define GROUPNAME "mygroup"
int main(int argc, char **argv) {
int tid;
int mytid = pvm_mytid();
pvm_joingroup(GROUPNAME);
pvm_barrier(GROUPNAME, 5);
int recv = pvm_recv(-1, MSG_MASTER);
pvm_upkint(&tid, 1, 1);
printf("(SLAVE %d): Message received from: %d\n", mytid, tid);
pvm_initsend(PvmDataDefault);
pvm_pkint(&mytid, 1, 1);
pvm_send(tid, MSG_SLAVE);
printf("(SLAVE %d): Unicast message sent\n", mytid);
pvm_lvgroup(GROUPNAME);
pvm_exit();
return 0;
}
|
Nowe funkcje systemu PVM zastosowane w przykładzie:
- int pvm_joingroup(char *group)
- Funkcja przyłącza zadanie, które wywołuję tę funkcję, do grupy dynamicznej o nazwie group. Pierwsze wywołanie tej funkcji dla grupy group powoduje także utworzenie tej grupy dynamicznej. W wyniku funkcja przekazuje numer procesu w grupie group (numeracja zaczyna się od wartości 0, a wartości mniejsze oznaczają błąd).
- int pvm_barrier(char *group, int count)
- Funkcja wstrzymuje proces, który ją wywołuje, do momentu, aż count procesów należących do grupy wywoła tę funkcję. Status wykonania operacji przekazywany jest w wyniku, a wartości mniejsze od zera sygnalizują błąd.
- int pvm_bcast(char *group, int msgtag)
- Funkcja wysyła komunikat z aktywnego bufora wyjściowego, zaopatrzony w etykietę numeryczną msgtag, do wszystkich procesów w grupie group, z wyjątkiem siebie samego. Status wykonania operacji przekazywany jest w wyniku, a wartości mniejsze od zera sygnalizują błąd.
- int pvm_lvgroup(char *group)
- Funkcja pozwala procesowi opuścić grupę dynamiczną. Status wykonania operacji przekazywany jest w wyniku, a wartości mniejsze od zera sygnalizują błąd.
Realizacja topologii pierścienia¶
Przykład programu typu “master”, który inicjuje przesyłanie “tokena”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #include <stdio.h>
#include <stdlib.h>
#include <pvm3.h>
#define SLAVENUMBER 4
#define GROUPNAME "mygroup"
#define MSGTAG 1234
int main(int argc, char **argv) {
int tids[SLAVENUMBER];
int token = 0;
pvm_joingroup(GROUPNAME);
pvm_spawn("slave", NULL, PvmTaskDefault, 0, SLAVENUMBER, tids);
pvm_barrier(GROUPNAME, SLAVENUMBER + 1);
pvm_initsend(PvmDataRaw);
pvm_pkint(&token, 1, 1);
pvm_send(pvm_gettid(GROUPNAME, 1), MSGTAG);
pvm_recv(-1, MSGTAG);
pvm_upkint(&token, 1, 1);
printf("(MASTER) TOKEN received: %d\n", ++token);
pvm_exit();
return 0;
}
|
Program typu “slave” realizujący topologię pierścienia:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <stdio.h>
#include <stdlib.h>
#include <pvm3.h>
#define SLAVENUMBER 4
#define GROUPNAME "mygroup"
#define MSGTAG 1234
int main(int argc, char **argv) {
int successor = 0, token = 0;
int tid = pvm_mytid();
int group_number = pvm_joingroup(GROUPNAME);
printf("(SLAVE %d) Number in the group: %d\n", tid, group_number);
pvm_barrier(GROUPNAME, SLAVENUMBER + 1);
if (group_number == pvm_gsize(GROUPNAME) - 1)
successor = pvm_parent();
else
successor = pvm_gettid(GROUPNAME, group_number + 1);
pvm_recv(-1, MSGTAG);
pvm_upkint(&token, 1, 1);
token++;
printf("(SLAVE %d) TOKEN received: %d\n", tid, token);
pvm_initsend(PvmDataRaw);
pvm_pkint(&token, 1, 1);
pvm_send(successor, MSGTAG);
pvm_exit();
return 0;
}
|
Nowe funkcje systemu PVM zastosowane w przykładzie:
- int pvm_gettid(char *group, int inum)
- Funkcja przekazuje w wyniku identyfikator tid procesu o inum numerze w grupie group.
- int pvm_gsize(char *group)
- Funkcja przekazuje w wyniku aktualną liczność grupy dynamicznej o nazwie group.
Realizacja topologii pierścienia w pojedynczym programie¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "pvm3.h"
#define NPROC 4
#define GROUPNAME "mygroup"
#define MSGTAG 1234
int main(int argc, char **argv) {
int successor = 0, token = 0;
int tid = pvm_mytid();
int group_number = pvm_joingroup(GROUPNAME);
srand(tid);
printf("%d: Number in the group: %d\n", tid, group_number);
pvm_barrier(GROUPNAME, NPROC);
if (group_number == pvm_gsize(GROUPNAME) - 1)
successor = pvm_gettid(GROUPNAME, 0);
else
successor = pvm_gettid(GROUPNAME, group_number + 1);
if (group_number == 0) {
pvm_initsend(PvmDataRaw);
pvm_pkint(&token, 1, 1);
pvm_send(successor, MSGTAG);
}
while(1) {
pvm_recv(-1, MSGTAG);
pvm_upkint(&token, 1, 1);
token = group_number;
printf("%d: TOKEN received: %d\n", tid, token);
sleep((rand() % 8) + 1);
printf("%d: TOKEN sent\n", tid, token);
pvm_initsend(PvmDataRaw);
pvm_pkint(&token, 1, 1);
pvm_send(successor, MSGTAG);
}
pvm_exit();
return 0;
}
|
Message Passing Interface (MPI)¶
Wybrane implementacje interfejsu MPI:
Przydatne zasoby internetowe dotyczące interfejsu MPI:
- Message Passing Interface Forum;
- Tutorial on MPI: The Message-Passing Interface (by William Gropp);
- Message Passing Interface (by Blaise Barney).
Pierwszy program¶
Pierwszy program “Hello World!”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #include <stdio.h>
#include "mpi.h"
int main(int argc, char **argv) {
int rank, size, namelen;
char host[150] = {0};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Get_processor_name(host, &namelen);
printf("Hello World! (Rank: %d\tHost: %s\tSize: %d)\n", rank, host, size);
MPI_Finalize();
return 0;
}
|
Zastosowane funkcje interfejsu MPI:
- int MPI_Init(int *argc, char ***argv)
- Funkcja inicjuje środowisko wykonawcze MPI – każdy proces musi wywołać tę funkcję (jedynie raz) przed wywołaniem jakiejkolwiek innej funkcji interfejsu MPI. Parametr argc to wskaźnik na liczbę argumentów, a argv to wektor argumentów głównej funkcji main – argumenty ty nie są jednak modyfikowane ani interpretowane w żaden sposób.
- int MPI_Comm_rank(MPI_Comm comm, int *rank)
- Funkcja przekazuje pod adresem rank identyfikator procesu (tzw. rank) w ramach komunikatora comm.
- int MPI_Get_processor_name(char *name, int *resultlen)
- Funkcja przekazuje poprzez tablicę name nazwę węzła, na którym wykonywany jest wywołujący ją proces; pod adresem resultlen zapisywana liczba znaków przekazanej nazwy węzła.
Schemat kompilacji i uruchamiania programów MPI¶
Schemat kompilacji programów MPI w systemie operacyjnym GNU/Linux jest następujący:
$ mpicc [NAZWA].c -o [NAZWA]
Uruchomienie N procesów programu [NAZWA] wymaga wydania następującego polecenia:
$ mpirun -np N [NAZWA]
Uruchomienie N procesów programu [NAZWA] na zdalnych komputerach wymaga przygotowania pliku tekstowego z nazwami tych komputerów [FILE] oraz wydania następującego polecenia:
$ mpirun -np N -hostfile [FILE] [NAZWA]
Możliwe także jest podanie nazw zdalnych komputerów bezpośrednio w linii poleceń:
$ mpirun -np N -host <host1,host2,...,hostM> [NAZWA]
Przykład podstawowej komunikacji pomiędzy procesami¶
Przykładowy program:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <stdio.h>
#include "mpi.h"
#define MSGTAG 1234
int main(int argc, char **argv) {
int i, rank, size, namelen;
char host[150] = {0};
char msg[50] = {0};
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Get_processor_name(host, &namelen);
printf("(Rank: %d\tHost: %s\tSize: %d)\n", rank, host, size);
if (rank == 0) {
for (i=1; i<size; i++) {
MPI_Recv(msg, 50, MPI_CHARACTER, MPI_ANY_SOURCE, MSGTAG, MPI_COMM_WORLD, &status);
printf("Message received: source = %d, msg = '%s'\n", status.MPI_SOURCE, msg);
}
} else {
snprintf(msg, 50, "Hello from node rank %d", rank);
MPI_Send(msg, 50, MPI_CHARACTER, 0, MSGTAG, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
|
Nowe funkcje interfejsu MPI zastosowane w przykładzie:
- int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
- Funkcja umożliwia wysłanie wiadomości zawartej w buforze pod adresem *buf o typie datatype do procesu o numerze rank równym dest w ramach komunikatora comm. Wysyłana wiadomość oznaczana jest etykietą tag, a parametr count określa liczbę elementów, o wskazanym typie, jakie mają być wysłane z podanego bufora.
- int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
- Funkcja realizuje blokujący odbiór wiadomości od procesu o numerze rank równym source (predefiniowana stała MPI_ANY_SOURCE podana jako parametr source pozwala odebrać wiadomość od dowolnego nadawcy) w ramach komunikatora comm o podanej etykiecie tag i typie danych datatype. Odebrana wiadomość zapisywana będzie pod adresem *buf, a parametr count określa maksymalną liczbę elementów o wskazanym typie, które można pobrać do podanego bufora. Pod adresem *status przekazany zostanie obiekt opisujący status odebranej wiadomości.
Typy danych interfejsu MPI i odpowiadające im typy języka C:
| MPI DATA TYPE | C DATA TYPE |
|---|---|
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | 8 binary digits |
Przykłady komunikacji grupowej¶
Broadcast – przykładowy program rozgłaszania wiadomości:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
#include <stdio.h> #include "mpi.h" int main(int argc, char **argv) { int rank, size, namelen; char host[150] = {0}; char msg[200] = {0}; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Get_processor_name(host, &namelen); if (rank == 0) { snprintf(msg, 50, "Hello from node %s rank %d", host, rank); printf("(%d) Broadcast message sent\n", rank); } MPI_Bcast(msg, 200, MPI_CHAR, 0, MPI_COMM_WORLD); if (rank !=0) { printf("(%d) Message received: '%s'\n", rank, msg); } MPI_Finalize(); return 0; }
- int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
Funkcja rozgłasza count wartości zawartych pod adresem *buffer o typie datatype od procesu o numerze rank równym root w ramach komunikatora comm. (Odbierane dane zapisywane są w pozostały procesach pod adresem *buffer).
Scatter – przykładowy program rozprowadzania wiadomości:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
#include <stdio.h> #include <stdlib.h> #include <mpi.h> #define ROOT 0 int main(int argc,char **argv) { int *my_array, *send_array; int rank, size, i; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); my_array=(int*)malloc(sizeof(int)); if (rank == ROOT) { send_array=(int*)malloc(size*sizeof(int)); for(i=0; i<size; i++) send_array[i] = i; } // MPI_Barrier(MPI_COMM_WORLD); MPI_Scatter(send_array, 1, MPI_INT, my_array, 1, MPI_INT, ROOT, MPI_COMM_WORLD); printf("(%d) Received value = %d\n", rank, *my_array); MPI_Finalize(); return 0; }
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
-
int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
-
int MPI_Allgather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
-
int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Algorytmy rozproszonego wzajemnego wykluczania¶
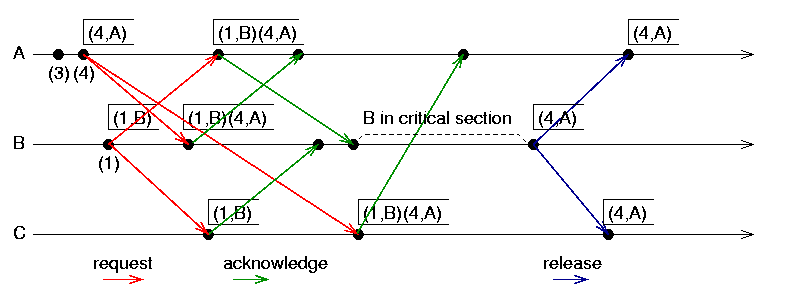
Algorytm Lamporta¶
Wymagania i założenia algorytmu:
- kanały komunikacyjne pomiędzy wszystkimi procesami \(p_1, p_2,..., p_N\) zachowują porządek FIFO,
- wszystkie procesy wykorzystują zegary logiczne Lamporta,
- każda wiadomość jest znakowana identyfikatorem i zegarem logicznym procesu nadawcy: \((p_i, ts_i)\),
- żądania dostępu do sekcji krytycznej, które mają mniejszą etykietę \((p_i, ts_i)\) mają priorytet nad żądaniami z większymi etykietami – etykieta \((p_i, ts_i)\) jest mniejsza od etykiety \((p_j, ts_j)\) jeżeli \(ts_i<ts_j\) lub jeżeli \(ts_i==ts_j\) oraz \(i<j\);
- każdy proces \(p_i\) utrzymuje kolejkę żądań \(request\_queue_i\), której elementami są etykiety: \((p_j, ts_j)\).
Algorytm:
- Żądanie dostępu do sekcji krytycznej przez proces \(p_i\):
- \(proces~p_i~rozgłasza~wiadomość~REQUEST(p_i, ts_i)~oraz~dodaje~etykietę~(p_i, ts_i)~do~własnej~kolejki~request\_queue_i\);
- \(kiedy~proces~p_j~odbiera~wiadomość~REQUEST(p_i, ts_i),~to~dodaje~odebraną~etykietę~do~własnej~kolejki\) \(oraz~odpowiada~nadawcy~żądania~wiadomością~REPLY(p_j, ts_j)\).
- Warunki zajęcia sekcji krytycznej przez proces \(p_i\):
- [L1]: \(proces~p_i~odebrał~wiadomości~od~wszystkich~pozostałych~procesów~z~etykietami~większymi~niż~(p_i, ts_i)\);
- [L2]: \(etykieta~(p_i, ts_i)~jest~pierwsza~w~kolejce~żądań~request\_queue_i\).
- Zwolnienie sekcji krytycznej przez proces \(p_i\):
- \(proces~p_i~usuwa~etykietę~(p_i, ts_i)~z~kolejki~żądań~request\_queue_i~i~rozgłasza~wiadomość~RELEASE(p_i, ts'_i)\);
- \(kiedy~proces~p_j~odbiera~wiadomość~RELEASE(p_i, ts'_i),~to~usuwa~etykietę~(p_i, ts_i)~z~własnej~kolejki~żądań\).
Ilustracja działania algorytmu Lamporta.
{kind=link}
Pytania
- Dlaczego powyższy algorytm wymaga zachowania kolejności FIFO w kanałach komunikacyjnych?
- Jaka powinna być kolejność etykiet w kolejkach \(request\_queue_i\)?
- Jaka jest złożoność komunikacyjna powyższego algorytmu?
- Jak zmodyfikować powyższy algorytm aby zmniejszyć złożoność komunikacyjną? (Podpowiedź)
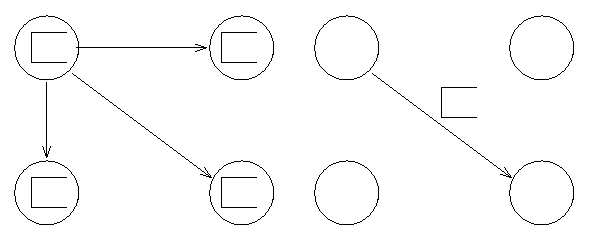{kind=link}
Zaliczenie¶
Zaliczenie laboratorium wymaga implementacji rozproszonego rozwiązania problemu przydziału zasobów i/lub wzajemnego wykluczania według poniższych zadań. Każdy proces rozwiązania powinien działać zgodnie z następującym schematem:
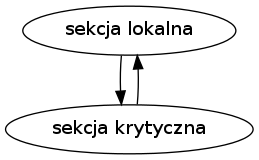
(sekcja krytyczna oznacza stan, w którym proces zajmuje współdzielony zasób).
Uwaga
Wszystkie rozwiązania muszą być w pełni rozproszone!
Zadania zaliczeniowe¶
Pijący filozofowie
Przy okrągłym stole siedzi \(F\) filozofów, którzy na przemian myślą (filozofują) oraz piją (wodę). Filozofujący filozof spontanicznie (w losowym momencie) przerywa myślenie, aby ugasić pragnienie. Na czas picia filozof potrzebuje wyłącznego dostępu do jednej spośród ustawionych na stole \(B\) butelek z wodą (\(B<F\)) oraz jednego spośród \(K\) kielichów (\(K<F\)). Relacja pomiędzy wartościami \(B\) i \(K\) nie jest z góry znana. Każdy z filozofów wykonuje zatem cyklicznie następujące czynności: myśli, zajmuje jakąś wolną butelkę i wolny kielich, nalewa, odkłada butelkę, pije, odkłada kielich i znowu myśli. Należy napisać program dla procesu filozofa zapewniający, że nie nastąpi zagłodzenie (zasuszenie) żadnego z filozofów. Butelki i kielichy należy traktować jako współdzielone zasoby.
Czytelnicy i pisarze
Do czytelni przychodzą dwojakiego rodzaju użytkownicy: czytelnicy i pisarze. Czytelnicy mogą korzystać z czytelni w trybie współdzielonym (kilku czytelników może korzystać z niej jednocześnie), a pisarze korzystają z niej w trybie wyłącznym (pisarz nie może współdzielić czytelni z czytelnikiem lub z innym pisarzem). Napisać programy dla procesu czytelnika i procesu pisarza, umożliwiające każdemu użytkownikowi skorzystanie ostatecznie z czytelni. Założyć znaną (stałą) liczbę procesów.
Wyciąg narciarski
Wyciąg narciarski o całkowitej nośności \(N\) kg wwozi na szczyt pojedynczych narciarzy. Każdy z \(S\) narciarzy waży łącznie ze sprzętem pewną ilość \(n_i\) kg ( \(n_i<N\) lecz \(\sum_{i=1}^{S}(n_i)>N\)). W każdym momencie suma wag \(n_i\) aktualnie zabranych narciarzy nie może przekroczyć \(N\). Po dotarciu na szczyt narciarze przez pewien czas zjeżdżają na nartach, a następnie ponownie ubiegają się o wwiezienie na szczyt. Napisać program dla procesu narciarza, umożliwiający każdemu narciarzowi wielokrotne korzystanie z wyciągu.
Stacja benzynowa
\(S\) samochodów korzysta cyklicznie ze stacji benzynowej o \(D\) stanowiskach dystrybucyjnych. Samochód podjeżdża na stanowisko o ile jest ono wolne. Po zatankowaniu, samochód zwalnia stanowisko i udaje się do dowolnej spośród \(K\) kas. Po obsłużeniu przez kasę, samochód opuszcza stację i udaje się na przejażdżkę. Należy przyjąć \(S>D>K\). Napisać program dla procesu samochodu. Dystrybutory i kasy należy traktować jako zasoby współdzielone w trybie wyłącznym.
Lotniskowce
\(S\) samolotów oraz \(L\) lotniskowców każdy z różną liczbą \(n_i\) stanowisk postojowych; \(S>\sum_{i=1}^{L}(n_i)\). Na każdym lotniskowcu znajduje się tylko jeden pas startowy, z którego korzystają zarówno samoloty startujące jak i lądujące. Pas może być używany tylko w trybie wyłącznym. Samolot ubiega się o dowolny spośród aktualnie wolnych pasów startowych. Napisać program dla procesu samolotu. Pasy i miejsca postojowe należy traktować jako zasoby.
Eskadra śmigłowców
Eskadra liczy \(H\) helikopterów, które lądują oraz startują z lądowiska złożonego z \(S\) pól startowych, a po wylądowaniu stacjonują w hangarze o pojemności \(P\) stanowisk postojowych. Należy przyjąć \(H>P>S\). Napisać program dla procesu helikoptera, umożliwiający mu wielokrotne cykle start-lot-lądowanie-postój w hangarze. Operacje startu i lądowania mogą być przeprowadzane współbieżnie (przez co najwyżej \(S\) helikopterów). Stanowiska startowe oraz postojowe należy traktować jako zasoby.
Cumy
Zatoka portowa z keją na \(N\) cum; \(S>N\) statków wymagających różnej liczby \(n_i\) cum. Statki wpływają do portu poprzez wąską śluzę, zdolną pomieścić zaledwie jeden statek. Każdy statek po wpłynięciu do portu natychmiast cumuje zgodnie z wymaganą dla jego wielkości liczbą cum. Po dokowaniu statek zwalnia cumy i opuszcza port poprzez śluzę. Napisać program dla procesu statku umożliwiający każdemu ze statków wielokrotne korzystanie z portu. Śluzę i cumy należy traktować jako zasoby.
Serwis komputerowy
System złożony z \(K\) komputerów, które niestety systematycznie wymagają serwisowania. Serwis posiada \(N\) stanowisk naprawczych umożliwiających jednoczesną naprawę do \(N\) maszyn. Przed naprawą każdy komputer musi być przyjęty na dowolnym spośród dostępnych \(S\) stanowisk przyjęć, a po naprawie wydawany jest również przez jedno dowolne z nich. Przyjmujemy: \(K>N>S\). Napisać program dla procesu komputera umożliwiający mu systematyczne serwisowanie wg powyższych zasad. Stanowiska przyjęć/wydań oraz naprawcze należy traktować jako zasoby.
Zasady zaliczania projektów¶
- Do każdego projektu należ dołączyć sprawozdanie (w formacie PDF, RTF lub
TXT), które powinno zawierać następujące informacje:
- definicja problemu (treść zadania);
- przyjęty model komunikacji (topologia połączeń, właściwości kanałów);
- dokładny opis protokołu wykorzystanego do rozwiązania problemu (opis protokołu powinien umożliwiać wykazanie jego poprawności);
- opis złożoności komunikacyjnej zastosowanego rozwiązania;
- krótki opis implementacji (plików źródłowych) oraz sposobu obsługi programu.
- Kryteria oceny projektów są następujące:
- terminowość oddania projektu,
- poprawność przyjętego rozwiązania,
- złożoność komunikacyjna rozwiązania,
- czytelność i dokładność sprawozdania,
- przejrzystość i czytelność kodu.