Obliczenia statystyczne¶
Projekt R¶
Projekt R to język i środowisko do przeprowadzania obliczeń statystycznych i rysowania grafów. Jest on dostępny (darmowo) na stronie http://www.r-project.org/.
Uruchamianie R na systemie operacyjnym Linux¶
- Wywołaj okno wykonywania komend ALT+F2 lub uruchom program Terminal.
- Wpisz komendę
R(wielka litera) i naciśnij Enter.
Interfejs użytkownika¶
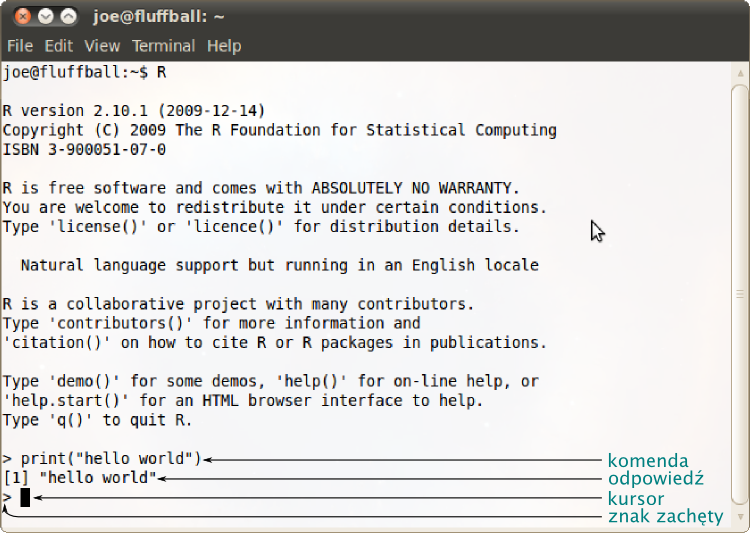
R jest kontrolowa ny przez wpisywanie komend opisujących operacje które mają zostać wykonane (i naciskanie ENTER).
Wypisaywanie wartości¶
Wypisywanie wartości funkcją print. Żeby wypisać napis hello wpisz:
print("hello")
Napisy podaje się w cudzysłowiu.
Żeby połączyć ze sobą dwa lub więcej napisy przed wypisaniem użyj funkcji paste jako argumentu funkcji print:
print(paste("hello", "world"))
Napisz funkcję która wypisze na ekranie ala ma kota.
Operacje matematyczne¶
R pozwala na wykonywanie operacji matematycznych. Można go używać do dodawania, odejmowania, mnożenia, dzielenia, potęgowania (dwie wersje), dzielenie całkowitoliczbowe i reszta z dzielenia:
2 + 2
2 - 2
10 / 3
10 * 3
10 ^ 3
10 ** 3
10 %/% 3
10 %% 3
Złożone działania można ujmowac w nawiasy:
4 ^ (1/2)
(10*1200 + 2*1000) / 0.22
Policz średnią z liczb 3.5 4 i 3.5
Odstępy między operatorami są ignorowane, więc 4*2 i 4 * 2 są traktowane tak samo.
Zmienne¶
R pozwala na definiowanie zmiennych. Możemy np. określić, że x ma być równe 2:
x = 2
Równoważnym sposobem definicji zmiennej x jest napisanie:
x <- 2
Żeby wypisac wartość x możemy znów zastosować funkcję print:
print(x)
Możemy teraz używać zmiennej w obliczeniach, np:
2*x + 1
Zmienna nie musi być liczbą, może być czymkolwiek:
napis <- "ala ma kota"
print(napis)
R rozróżnia małe i wielkie litery, więc x i X to dwie różne zmienne.
Zdefiniuj zmienne imie, nazwisko, indeks i przypisz im swoje dane.
Operacje na wektorach¶
Zdefiniuj wektor a zawierający liczby 1, 2, 3, 4 i 5. Wektory definiuje się za pomocą funkcji c
a <- c(1, 2, 3, 4, 5)
Zdefiniuj w ten sam sposób wektor b zawierający liczby 1, 5, 10, 15 i 20.
Wektory można też definiować jako sekwencje liczb całkowitych, podając początek i koniec sekwencji za pomocą operatora :. Poniżej zefiniowany jest wektor licz całkowitych od 1 do 100:
c <- 1:100
Można też definiować wektory jako sekwencje używając funkcji seq. Jako kolejne argumenty funcji należy podać wartośc początkową wektora, jego wartość końcową i wartość różnicy między poszczególnymi elementami. Zdefiniuj wektor od wartości -1 do 1 z elementami co 0.2:
d <- seq(-1, 1, .2)
Wypisz zawartość każdego z wektorów wpisując jego nazwę (nazwę zmiennej do której jest przypisany:
a
b
c
Na wektorach można wykonywać operacje matematyczne w taki sam sposób jak na liczbach. Wykonaj poniższe operacje i zaobserwuj wyniki:
a + 2
a - 2
a * 2
a / 2
a ** 2
Mając dwa wektory równej długości lub dwa wektory gdzie długość pierwszego jest wielokrotnością długości drugiego można także wykonywać operacje używając dwóch wektorówi. W takim wypadku każda kolejna wartość z pierwszego wektora jest poddana operacji używając odpowiedniej jednej wartości z drugiego wektora.
a <- 1:20
b <- c(1, -1)
a + b
a - b
a * b
a ** b
Wczytywanie danych z pliku CSV¶
Pobierz plik dane.csv i zapisz go w katalogu /home/student.
Wczytaj dane do R za pomocą funkcji read.csv. Jako pierwszy argument podaj nazwę pliku (lub lokalizacje pliku, jeśli plik znajduje się w innym katalogu). Drugi argument mówi czy pierwszy wiersz każdej z kolumn powinien być traktowany jako nagłówek – w tym wypadku tak. Trzeci argument wskazuje co jest separatorem komórek w pliku – tutaj przecinek.
read.csv("dane.csv", header = TRUE, sep = ",")
Zawartość pliku zostanie wypisana. Żeby korzystać z niej później przypisz ją do zmiennej dane. Ta zmienna będzie teraz przechowywać tabelę danych.
dane <- read.csv("dane.csv", header = TRUE, sep = ",")
Żeby odwołać się do jednej z kolumn tabeli użyj operatora $ i podaj nagłówek kolumny. Uzyskuje się w ten sposób wektor którego elementami są poszczeŋólne komórki kolumny.
dane$płeć
Można także odwołać się do tylko jednego (np. 21-szego) elementu kolumny:
dane$płeć[21]
Można także wyciągnąć z kolumny jej fragment (np. wszystkie elementy od 50-tego do 100-ego włącznie):
dane$płeć[50:100]
Odwołując się do jakiejś kolumny możemy (między innymi) zobaczyć występują w niej wartości. Użyj do tego funkcji unique i podaj kolumnę tabeli jako argument. Wykonując poniższą komendę można zobaczyć jakie wartości przyjmują komórki w kolumnie płeć.
unique(dane$płeć)
Analogicznie, żeby zobaczyć jakie są unikalne wartości w kolumnie wiek, wykonaj poniższą funkcję:
unique(dane$wiek)
Aby wypisać wszystkie tytuły kolumn użyj funkcji colnames dla tabeli dane:
colnames(dane)
Analogicznie można uzyskać tytuły wierszy za pomocą funkcji rownames, ale w tabeli dane wiersze nie są nazwane tylko ponumerowane.
Wypisz zbiór unikalnych wartości dla każdej z kolumn w tabeli.
Podstawowe funkcje statystyczne¶
R może obliczyć korelację między kolumnami tabeli. Użyj w tym celu funkcji cor:
cor(dane$wiek, dane$wzrost)
Oblicz korelacje dla wszystkich kolumn z wartościami liczbowymi.
W podobny sposób oblicz kowariancję między kolumnami za pomocą funkcji cov.
Można obliczyć średnią dla wszystkich kolumn w tabeli za pomocą funkcji mean.
mean(dane)
Ewentualnie można obliczyć średnią dla poszczególnych kolumn używając ich nazw.
mean(dane$waga)
mean(dane$wzrost)
mean(dane$wiek)
Podobnie działają funkcje dla obilczania odchylenia standardowego sd oraz wariancji var. Oblicz wariancję i odchylenie standardowe dla każdej z kolumn tabeli dane
Funkcje mediany median, minimum min, maksimum max i rozmiaru zbioru length działają tylko na poszczególnych kolumnach. Oblicz medianę, minimum, maksimum i długość dla każdej z kolumn tabeli dane.
R pozwala na podsumowanie danego zbioru danych za pomocą funkcji summary. Dla kolumn z zawartością liczbową wypisywane są minimum, maksimum, średnia, mediana i wartości pierwszego i trzeciego kwartyla. Dla kolumn zawierających napisy przedstawiony jest histogram.
Test t-Studenta¶
Test t-Studenta służy do porównywania między sobą dwóch populacji (zbiorów danych). W związku z tym przygotuj dwie populacje dzieląc kolumnę wiek na pół.
dł <- length(dane$wiek) # policz długość kol. wiek i zapisz ją do zm. dł
dane.wiek1 <- dane$wiek[1:(dł%/%2)] # wybierz wiek z pierwszej połowy kolumny i zapisz do zm. dane.wiek1
dane.wiek2 <- dane$wiek[(dł%/%2):dł] # wybierz wiek z drugiej połowy kolumny i zapisz do zm. dane.wiek2
Wykonaj test t-Studenta za pomocą funkcji t.test. Jako dwa argumenty podaj dwie populacje. Zakładamy tu że dwie populacje są niezależne od siebie.
t.test(dane.wiek1, dane.wiek2)
Jeśli populacje są zależne od siebie należy umieścić informację o tym jako trzeci argument.
t.test(dane.wiek1, dane.wiek2, paired = TRUE)
Podziel kolumnę wzrost na dwie populacje i wykonaj na nich powyższe testy t-Studenta.
Regresja¶
Wprowadź do środowiska R dane prognozy pogody. Wektor dzień wskazuje w którym dniu robiono pomiary. Wektor temp.dzień to pomiary temperatury w poszczegolne dni, a wektor temp.noc to pomiar temperatury w nocy.
dzień <- 1:16
temp.dzień <- c(2, 1, 1, 0, -3, -2, -1, -4, -2, -2, -1, 2, 4, 7, 6, 6)
temp.noc <- c(-1, -2, -6, -8, -5, -4, -3, -4, -7, -8, -8, -7, -4, -1, 0, -1)
Oblicz średnią, minimum, maksimum, odchylenie standardowe i wariancję dla wektorów temp.dzień i temp.noc.
Za pomocą regresji liniowej skonstruuj model który pozwoli na przewidzenie temperatury 17 dnia. W tym celu wykorzystaj funkcję lm.
Jako argument funkcji podaj równanie funkcji liniowej $text{temp.dzień} = b_0 + b_1 * text{dzień}$. Taka funkcja jest zapisywana w R po prostu jako temp.dzień ~ dzień. Wywołanie funkcji lm wygląda więc tak:
lm(temp.dzień ~ dzień)
Jako wynik zwrócony zostanie wektor współczynników (coefficients) równania $b$. Pierwsza z wypisanych wartości to $b_0$ a kolejny to $b_1$. Możemy więc obliczyć temperaturę w 17 dzień ze wzoru na funkcję:
przewidywana.temp <- -2.4500 + 0.3912 * 17
print(przewidywana.temp)
Wynik uzyskany przez regresję liniową jest tylko pewną aproksymacją, i jest niedokładny, jeśli dane nie mają postaci liniowej (tak jak u tu).
R pozwala także na łatwe zobrazowanie wyników regresji liniowej.Żeby narysować wykres przedstawiający wykres temp.dzień należy użyć funkcji plot:
plot(temp.dzień)
Żeby pokazać funkcję liniową obliczoną przez regresję liniową przygotuj najpierw wektor zawierający wartości tej funkcji ze wzoru funkcji liniowej:
temp.dzień.reg <- -2.4500 + 0.3912 * dzień
Teraz dorysuj ten wektor na wykres jako linię za pomocą funkcji lines:
lines(temp.dzień.reg)
Żeby pokazać na wykresie także przewidywany wynik dla 17 dnia należy najpier utworzyć nowe wektory które składają się ze starych wektorów dzień i temp.dzień z dodanymi odpowiednio dniem 17 i wartością temperatury dla tego dnia.
dzień.więcej <- c(dzień, 17)
temp.dzień.więcej <- c(temp.dzień, przewidywana.temp)
Rozszerz także wyniki regresji do 17 dni:
temp.dzień.reg.więcej <- -2.4500 + 0.3912 * dzień.więcej
Teraz narysuj nowy wykres:
plot(temp.dzień.więcej)
lines(temp.dzień.reg.więcej)
Oblicz przewdiywaną temperaturę w 17 noc używając wektora temp.noc. Narysuj wykres przedstawiający 17 temperatur w nocy i linię tegresji liniowej.
Rysowanie wykresów¶
Wprowadź wektor przedstawiający oceny uzyskane przez studentów:
oceny <- c(4.5, 3.0, 2.0, 4.0, 4.5, 5.0, 2.0, 3.0, 3.0, 4.0, 3.5)
Wykres słupkowy¶
Funkcja barplot służy do rysowania wykresów słupkowych.
barplot(oceny)
Słupki można pokolorować za pomocą drugiego argumentu funkcji – col i podając napis wskazujący kolor (w j. angielskim):
barplot(oceny, col = "red")
Można także okreslić tytuł, podtytuł, i tytuły osi wykresu dodając argumenty main, sub, xlab i ylab:
barplot(oceny, col = "red", main = "Oceny", sub = "Egzamin poprawkowy", xlab = "Student", ylab = "Ocena")
Tytuły pod kolumnami mozna dodać za pomocą argumentu names. Etykiety są wektorem który odpowiada liczebnością liczbie elementów wektora oceny.
studenci <- c("71740", "71741", "71742", "71743", "71744", "71745", "71746", "71747", "71748", "71749", "71750")
barplot(oceny, col = "red", main = "Oceny", sub = "Egzamin poprawkowy", xlab = "Student", ylab = "Ocena", names = studenci)
Wykres punktowy¶
Wykres punktowy wykonuje się funkcją dotchart. Funkcja ta działa identycznie jak wykres słupkowy. Jedyną różnicą jest to, że zamiast nadawać etykiety za pomocą parametry names należy to zrobić za pomocą parametry labels:
dotchart(oceny, labels = studenci)
Narysuj wykres punktowy ocen, dodaj kolor punktów, dodaj tytuły wykresu, oznacz osie i nadaj etykiety danych.
Wykres częstotliwości¶
Funkcja hist pozwala na narysowanie wykresu słupkowego pokazującego częstotliwość wystepowania (histogram) danego wektora:
hist(oceny)
Ustaw kolor słupków na niebieski dodając drugi argument col:
hist(oceny, col="blue")
Ogranicz liczbę słupków do 3 dodając argument breaks:
hist(oceny, col="blue", breaks=3)
Dodaj tytuł, podtytuł, i tytuły osi wykresu dodając argumenty main, sub, xlab i ylab:
hist(oceny, col="blue", main="Histogram ocen", sub="Egzamin poprawkowy", xlab="Oceny", ylab="Liczba wystąpień")
Tytuły pod kolumnami można dodać za pomocą argumentu names lub nad kolumnami za pomocą labels:
etykiety <- c("ndst", "dst", "dst+", "db", "db+", "bdb")
hist(oceny, col="blue", main="Histogram ocen", sub="Egzamin poprawkowy", xlab="Oceny", ylab="Liczba wystąpień", labels=etykiety)
Narysuj histogramy dla płci, wieku, wzrostu i wagi z tabeli dane. Każdy wykres podziel na odpowiednią liczbę słupków, pokoloruj i nadaj tytuły.
Wykres kołowy¶
Za pomocą funkcji subset wyciągnij z kolumny płeć tabeli dane tylko te które są kobietami i zapisz do zmiennej k. Następnie zrób tak samo z mężczyznami i zmienną m. Funkcja subset przyjmuje dwa argumenty z czego pierwszy to wektor z którego ma wyciągać dane, a drugi to warunek jaki muszą spełnić te dane żeby być uwzględnione w wyniki (podobnie jak funkcja LICZ.JEŻELI w OOO):
k <- subset(dane$płeć, dane$płeć=="K")
m <- subset(dane$płeć, dane$płeć=="M")
Policz liczbę kobiet i mężczyzn w tych wektorach żeby uzyskać liczby kobiet i mężczyzn w tabeli dane.
licz.k <- length(k)
licz.m <- length(m)
Za pomocą funkcji pie narysuj wykres kołowy. Najpierw w tym cleu nalezy umieścić liczbę kobiet licz.k i liczbę mężczyzn licz.m w jednym wspólnym wektorze.
licz <- c(licz.k, licz.m)
pie(licz)
Dodaj tytuły i etykiety do wykresu (tak jak w wykresie punktowym).
Wykonaj wykres kołowy dla ocen pokazujących ile osób zdało (oceny>2) i ile osób nie zdało (oceny<=2).
Wykres pudełkowy¶
Za pomocą funkcji boxplot utwórz wykres pudełkowy dla wektorów dane.wiek1 i dane.wiek2. Podaj wektory jako dwa pierwsze argumenty funkcji:
boxplot(dane.wiek1, dane.wiek2)
Co pokazuje ten wykres?
Dodaj tytuły i etykiety wykresu (tak jak w wykresie słupkowym).
Wykres pudełkowy można także zrobić od razu dla całej tabeli dane podając ją jako pierwszy argument. Jest to przydatne, gdy dane wejściowe mają być ze sobą porównane (w przypadku tabeli dane ten wykres nie ma sensu).
boxplot(dane)
Eksport wykresów¶
Zeby zapisać wykres jako obraz (np. żeby umieścić go w jakimś dokumencie) należy przed utworzeniem grafu odpowiednią funkcją wywołać najpierw funkcję png i jako pierwszy argument podać ścieżkę do pliku gdzie ma być zapisany wykres. W poniższym przykładzie plik zostanie utworzony na pulpicie i będzie miał nazwę wykres.png.
png("~/Desktop/wykres.png")
Po zakończeniu edycji wykresu należy wywołać funkcję dev.off bez argumentów. Plik zostanie wtedy zpaisany na dysk.
dev.off()
Wyeksportuj w ten sposób po jednym wykresie każdego typu.
Można w ten sposób także eksportować do innych formatów, m.in:
postscriptjpegbmptiff