Software framework for explanatory modeling of big data (LUCID)
Lucid is an R&D project led by the Institute of Computing Science, Poznan University of Technology, Poland, funded by the National Centre for Research and Development, Poland (DZP/TANGO2/396/2016, 2017-2019). The goal of the project is to design and implement a toolbox of explanatory modeling for Apache Spark and to make it available to entities from business and academia. Explanatory modeling leverages the techniques of machine learning for automatic acquisition of transparent models from data produced by arbitrary processes, including business operations, product development/prototyping, scientific experimentation, etc., for making predictions, performing classification, clustering and other activities related to data analytics. Transparency is achieved by representing models as symbolic (algebraic or logic) expressions and rules of the form “if ... then ...”. Such models, in addition to serving as typical predictors (classifiers, regressors, etc.), offer insight into the nature of the process in question and facilitate various forms of explanation: explanation of predictions being made, their causes, interactions between parameters that characterize the process, etc. These features, though essential in many application areas, are largely absent in the mainstream machine learning methods like neural networks, random forests or support vector machines.
The following use case illustrates this problem:
John supervises a complex production process controlled by a range of input parameters, and uses a neural network to predict the yield of the process based on those parameters. This works fine, but one day the company decides to change the subcontractor, who delivers a raw material of slightly different characteristics. John updates the input parameters according to that new characteristics, and the model in response outputs a prediction of yield that is radically different from the values predicted in the past. John is puzzled. Why is such a minor change causing so substantial variation in forecast? What is the reason behind this recommendation? Was that one characteristics of the raw material that caused that change, or maybe a combination of several characteristics? Should he trust the model? Unfortunately, the model used by John has thousands of internal parameters that John cannot make sense of. The model is not transparent.
Our team developed a range of algorithms for building transparent models and applied them to multiple real-world problems. For instance, in applications concerning climate science, we used past measurements to synthesize mathematical formulas that explained how global temperature depends on multiple environmental factors. The formulas, obtained with little human intervention and domain-specific knowledge, can be easily inspected and verified by experts:
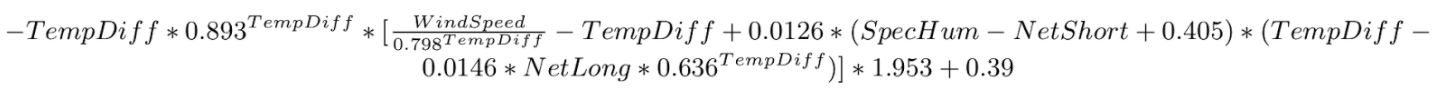
In another application, we induced models in the form of rules that explained the environmental impact of various methods of synthesizing nanoparticles, like this one:
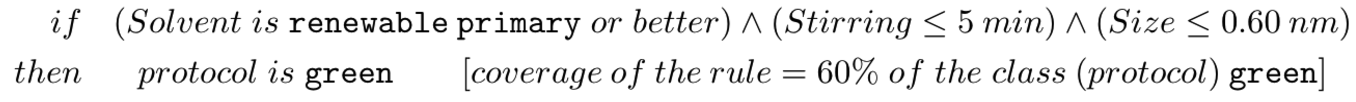
In Lucid, we intend to disseminate those methods and make them available on the market as a professional, versatile, scalable, and efficient software product built upon Apache Spark, the most popular and dynamically developing big data analytics platform. By extending Spark, rather than building from scratch, explanatory modeling will become available in solutions and products based on the existing deployments of Spark. The users of Lucid will be able to apply our methods side-by-side with the conventional algorithms or explain existing models that lack explanatory capabilities (like neural networks or random forests). Lucid will leverage Spark’s performance, maintain its generic and open character, and so render itself available virtually wherever there is a need for explanatory analytics of business processes (production, logistics, marketing, etc.) as well as scientific and R&D processes, in particularly those that generate large volumes of data.
Popular science description
Computer science recently experienced two technological breakthroughs: unprecedented growth of storage capabilities and cheap access to computing power. These developments, combined with progress in artificial intelligence (AI) gave rise to a multitude of recent achievements, epitomized with impressive capabilities of pattern recognition (e.g., competent annotation of images with human-like descriptions like "two young girls are playing with lego toy"), automated translation (also combined with simultaneous speech recognition and speech synthesis), and the dawn of autonomous vehicles (e.g., Google car).
These and other examples clearly evidence the increasing performance of models — formalisms that capture the knowledge about a problem — employed in contemporary intelligent systems. In many contexts, however, predictive accuracy is not enough: what becomes equally important — and sometimes essential — is the capability to explain the processes in question, i.e., provide a transparent description of the nature of underlying phenomena, and/or justify the suggestions made by a model. A physician will usually refrain from diagnosing when provided only with bare probabilities of particular medical conditions for a given patient, and will seek explanation and justification of those indications. An engineer responsible for maintaining an industrial plant is interested not only in finding the optimal setup of the equipment, but also in a model that clearly shows and explains how the efficiency of that process depends on its parameters. For a scientist, even the most accurate prediction of an experimental outcome will not be of much use if not accompanied by a compelling and legible theory or hypothesis. With the growing complexity of studied phenomena, some form of explanation becomes essential.
Most AI methods that are contemporary paragons of performance have little to offer when it comes to the explanation of models they implement. For instance, artificial neural networks, in particular the deep ones, are essentially black boxes that implement complicated nonlinear mappings encoded with numerous parameters, the number of which may nowadays easily reach millions. To perform well, pattern recognition methods often need to rely on thousands of image features. Computerized translation must often rely on huge repositories and statistics of phrases. The complexity of these and similar models is too high to render them intelligible to humans.
In the project New Computational Paradigms for Explanatory Modeling of Complex Systems, funded by the National Science Centre and conducted in our group in the years 2011-2014, we developed algorithms for explanatory modeling of phenomena and processes, and proved their usefulness in several application areas. The methods we proposed therein allow automatic acquisition of transparent, i.e., legible for humans, models from data — also big data — produced by scientific or business processes, represented as symbolic (algebraic or logic) expressions or rules (of the form “if ... then ...”). In one of our applications concerning climate science and global warming, we automatically induced, from past measurements, legible mathematical formulas explaining how global temperature depends on the concentration of greenhouse gases, solar activity, volcanic eruptions and activity of major ocean circulations. In another application, we induced — again automatically, with little domain-specific knowledge — readable decision rules that explained the environmental impact of various methods of synthesizing nanoparticles. In yet another area, we used our algorithms to discover new biomarkers intended to improve diagnosing of amyotrophic lateral sclerosis (ALS), a severe neurological condition.
In this project, dubbed LUCID, we intend to disseminate those promising and verified methods and make them available in both business and in R&D. Rather than developing software from scratch, we will build upon Apache Spark, the most popular and dynamically developing big data analytics platform, natively prepared to work in cloud environments. By extending this framework, our explanatory modeling methods will become easily available in solutions and products currently in use in the existing deployments of Apache Spark, which operates not only in renowned companies, like Amazon, Baidu, Groupon, TripAdvisor, or Yahoo, but also in R&D and scientific organizations, like NASA. The prospective users of Lucid will be able to apply our methods to their data side-by-side with the conventional algorithms, or alternatively use them to explain the models induced by techniques with little or no explanatory capabilities (like neural networks mentioned above). Our business partner in Lucid will become the main provider of this technology and thus beneficiary of the project, alongside with the final users of Apache Spark. Lucid will maintain the generic and open character of Apache Spark, and so render itself available in a broad spectrum of areas, virtually wherever there is a need for explanatory analytics of business processes (production, logistics, marketing, etc.) as well as scientific and R&D processes that involve complex phenomena and generate large volumes of data.
Survey
One of activities of the project involved conducting a survey on the usage patterns of Apache Spark. In the second part of the project, we've opened the survey to a wider group of respondents. If you have some experience with using Apache Spark in data analytics, and/or are interested in explanatory modeling, we kindly ask you to complete the survey. The link below will take you to the survey (which also features an intro explaining the rationale of explanatory modeling and the LUCID project).
Follow this link to complete the survey.