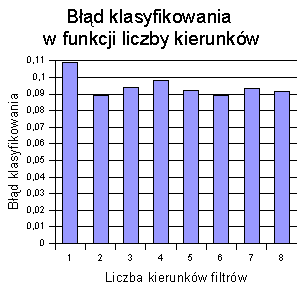Piotr Kalinowski, Magdalena Ławrynowicz
$Date: 2004/06/15 22:44:10 $
Celem projektu jest napisanie programu rozpoznającego obszary pokryte roślinnością na zdjęciach lotniczych. Do tych obszarów należą lasy, łąki i pola uprawne.
Klasyfikacja obszarów odbywa się na poziomie poszczególnych punktów obrazu. Każdy punkt może zostać przydzielony do jednej z dwóch klas: obszar zalesiony lub inny obszar. Kryterium oceny jest błąd klasyfikowania, czyli stosunek liczby błędnie zaklasyfikowanych punktów do wszystkich punktów obrazu.
Zbiór danych liczy 4 barwne obrazy, będące zdjęciami lotniczymi w paśmie widzialnym. Zdjęcia przedstawiają fragmenty obszaru gminy Warszawa Rembertów. Zdjęcia mają rozmiary ok. 1050x730 pikseli. Dla ułatwienia obrazy zostaną podzielone na mniejsze. Obszary wegetacji na zdjęciach można podzielić na różne kategorie - lasy, łąki, pola itd. Na obszarach zalesionych można łatwo zauważyć jaśniejsze i ciemniejsze drzewa - prawdopodobnie są wśród nich drzewa liściaste i iglaste.
Uczenie: tak
Oparte na cechach
Podejście pośrednie
Image-driven
Charakterystyczną cechą problemu jest rozpoznawanie obszarów, a nie obiektów. Stąd nie ma tu zastosowania np. wykrywanie krawędzi. Wydaje się uzasadnione klasyfikowanie poszczególnych punktów obrazu. Jeden obraz składa się z różnych obszarów, zatem nie można klasyfikować całych obrazów, natomiast podział na większe niż punkt jednostki klasyfikacji wydaje się sztuczny i wymagałby dodatkowego nakładu pracy. Istnieje tu jednak pewna trudność. Poszczególne punkty obrazu, składające się na widok np. drzewa, znacznie różnią się między sobą. Inaczej wygląda np. fragment korony, a inaczej fragment cienia drzewa. Zatem poprawne klasyfikowanie punktów w oderwaniu od sąsiedztwa byłoby nieskuteczne. Stąd zastosowana metoda powinna to sąsiedztwo uwzględniać.
Zastosowana metoda opiera się na filtrze Gabora, który tworzy wektor cech dla każdego punktu, stosowany następnie do klasyfikacji. Filtr Gabora można krótko scharakteryzować jako zespoloną sinusoidę, modulowaną dwuwymiarową funkcją Gaussa. Zastosowanie funkcji Gaussa powoduje, że punkty położone bliżej środka filtra mają większy wpływ na wynik niż punkty leżące dalej. Najważniejszymi parametrami filtra są skala i kierunek. Skala określa częstotliwość sinusoidy, natomiast kierunek określa kąt, o jaki jest ona obrócona. Zastosowanie filtra do punktu obrazu odbywa się poprzez nałożenie filtra na obraz i dodanie iloczynów wartości pikseli (jasności) oraz liczb sprzężonych do odpowiednich współczynników filtra. W ten sposób uzyskujemy liczbę zespoloną, będącą wartością odpowiedzi filtra dla punktu leżącego w centrum fragmentu obrazu pod nim. Zestaw filtrów o różnych skalach i kierunkach, zastosowany do obrazu w tym samym punkcie centralnym, daje wektor liczb zespolonych, opisujących punkt. Wygenerowane w ten sposób wektory dla wszystkich punktów obrazu lub jego fragmentu, wraz z maską bitową, dają zbiór uczący, który służy następnie do wygenerowania klasyfikatora.
Dla danego obrazu I(x, y) dyskretna transformacja Gabora zdefiniowana jest następująco:
![]()
gdzie s i t są zmiennymi rozmiaru maski filtra, a
![]() jest
sprzężeniem funkcji
jest
sprzężeniem funkcji
![]() ,
która jest zespoloną sinusoidą, modulowaną funkcją Gaussa:
,
która jest zespoloną sinusoidą, modulowaną funkcją Gaussa:
![]()
gdzie m oznacza skalę, n – kierunek
(orientację),
![]() – częstotliwość modulującą. Współczynniki
– częstotliwość modulującą. Współczynniki
![]() i
i
![]() wyznacza
się następująco:
wyznacza
się następująco:
![]()
![]()
Pozostałe zmienne zdefiniowane są następująco:
![]()
![]()
![]()
![]()
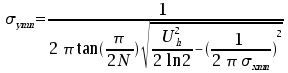
M oznacza liczbę skal, natomiast N – liczbę
kierunków.
![]() i
i
![]() są odpowiednio najwyższą i najniższą częstotliwością. Przyjęto
wartości
są odpowiednio najwyższą i najniższą częstotliwością. Przyjęto
wartości
![]() i
i
![]() .
.
Projekt został zrealizowany w języku Java, jako rozszerzenie programu Green, wykonanego przez Piotra Dachterę i Piotra Jurgę w roku 2001. Program wyposażony jest w graficzny interfejs użytkownika. Jest on przydatny do wizualizacji wyników klasyfikowania i umożliwia podgląd obrazów. Metoda rozpoznawania obrazów, oparta na filtrze Gabora, została dodana do programu jako dynamicznie dołączany moduł, tzw. wtyczka (plugin). Do klasyfikacji zastosowano klasy biblioteki WEKA. Do zarządzania kodem źródłowym wykorzystano system CVS. Do testów modułowych zastosowano klasy JUnit.
Najpierw tworzony jest zestaw filtrów, różniących się skalą i kierunkiem. Wszystkie filtry w zestawie mają ten sam rozmiar, dany jako parametr. Przyjęto, że filtry o kształcie kwadratowym. Inne parametry, takie jak odchylenie standardowe funkcji Gaussa, obliczane są na podstawie skali i kierunku. Sposób ich wyznaczania podaje praca [1]. Zestaw filtrów stosowany jest do wszystkich punktów obrazu (lub jego fragmentu). Wyniki traktowane są jako zbiór uczący i służą do wygenerowania klasyfikatora. Każdy punkt stanowi jeden przykład uczący (decyzja pobierana jest z maski). W obecnej implementacji do tworzenia klasyfikatora używana jest klasa J48 z biblioteki WEKA, która buduje drzewo decyzyjne.
Utworzony klasyfikator można zastosować do dowolnego obrazu. W tym przypadku również najpierw wyliczane są wartości odpowiedzi filtrów dla wszystkich punktów obrazu. Następnie każdy punkt klasyfikowany jest za pomocą uzyskanego wcześniej klasyfikatora.
Do pomiarów, jako obraz uczący, wykorzystano niewielki obraz small.jpg wraz z maską smallmask.gif. Obrazem testującym był obraz 1.jpg. Przygotowanie klasyfikatora jest dość czasochłonnym procesem. Zastosowanie kwadratowego filtra o rozmiarze FxF do obrazu o rozmiarach MxN wymaga o(M*N*F2) operacji na liczbach zespolonych. Do tego dochodzi koszt budowy klasyfikatora - dla każdego punktu tworzony jest obiekt klasy Instance z biblioteki WEKA, następnie ze zbioru tych obiektów indukowane jest drzewo decyzyjne. Testowanie metody na obrazie testującym jest szybsze - pomijany jest etap uczenia klasyfikatora. Pomiary przeprowadzono dla różnej liczby orientacji, skal i rozmiarów filtrów.
Zależność błędu klasyfikowania od rozmiaru filtra przedstawia
Wykres 1.
W
tym pomiarze zastosowano 3 skale (częstotliwości) i 2 orientacje
(kierunki). Jak widać, początkowo trafność rośnie wraz z rozmiarem
filtra (błąd spada), jednak dla filtrów większych niż
jedenaście trafność powoli się pogarsza. Możliwym wyjaśnieniem jest
wpływ rozmiaru elementów tekstury, które w przypadku
zdjęć lotniczych prawdopodobnie wynoszą do ok. 5 punktów.
Zatem dla większych filtrów klasyfikator opiera się częściowo
na przypadkowych zależnościach, które pogarszają wyniki.
Wyjątkiem od tej reguły okazał się tylko zestaw filtrów o
rozmiarze 9. W jego przypadku błąd jest większy niż dla 7 i 11.
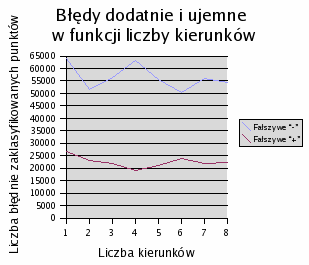
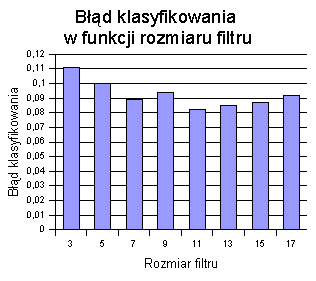
Na następnym wykresie przedstawiono zależność błędów dodatnich i ujemnych.
Liczba błędów dodatnich jest większa niż ujemnych. (Błąd dodatni oznacza błędne zaklasyfikowanie punktu, nie należącego do lasu, jako obszaru zalesionego; błąd ujemny, analogicznie, oznacza błędne zaklasyfikowanie lasu jako obszaru niezalesionego). Widać, że błąd “+” konsekwentnie spada dla coraz większych rozmiarów filtrów, natomiast błąd “-” jest bardziej nieregularny i powoli rośnie.
Zależność błędu klasyfikowania od liczby orientacji (kierunków) zestawu filtrów przedstawiają poniższe wykresy.
|
|
|
|---|
Pomiary wykonano przy pomocy filtrów o średnicy 7 punktów, dla 3 skal. Błąd klasyfikowania dla jednej orientacji wynosi około 0,11. Dla większej liczby błąd spada nieco poniżej 0,1, po czym raz wzrasta, a raz maleje. Trudno tu znaleźć jakąś regularną zależność. Wzrost liczby filtrów o różnych orientacjach nie przekłada się na lepszą trafność klasyfikowania. W badanym zakresie najmniejszą wartość błędu uzyskano dla 6 orientacji. Była ona jednak prawie identyczna, jak dla zaledwie dwóch.
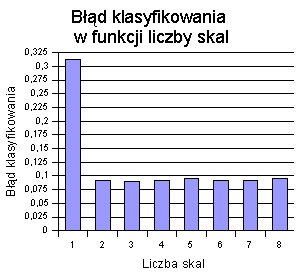
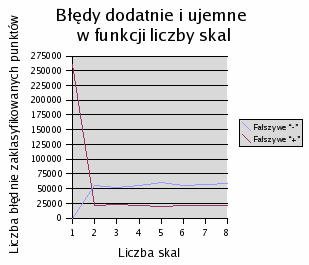
Poniższy wykres przedstawia zależność błędu klasyfikowania od liczby skal (czyli liczby różnych częstotliwości).
|
|
|
|---|
Pomiarów dokonano przy pomocy filtrów o rozmiarze 7 i o 2 orientacjach. W przypadku jednej skali analizowana jest jedynie składowa stała, a więc średnia jasność punktów w obrębie filtra, ważona funkcją Gaussa. Drzewo decyzyjne po obcięciu (ang. pruning) jest w tym przypadku trywialne:
J48 pruned tree
------------------
: 1
(36990.0/17658.0)
Number of Leaves : 1
Size of the tree
: 1
Wszystkie punkty są w tym przypadku klasyfikowane do klasy większościowej (lasy). Nic dziwnego, że błąd klasyfikowania wynosi ponad 0,3. Taką część obrazu testującego stanowią obszary niezalesione.
Po dodaniu drugiej skali błąd spada poniżej 0,1. Dalsze zwiększanie liczby skal, wbrew oczekiwaniom, nie przynosi już poprawy.
Dla pojedynczego kierunku i zaledwie dwóch skal uzyskać można bardzo proste drzewo, które jednak daje stosunkowo dobre wyniki (błąd klasyfikowania na poziomie 0,103):
J48 pruned tree
------------------
0x0.0 <= 7.964367403431543E17: 1 (21608.0/3758.0)
0x0.0 > 7.964367403431543E17: 0 (15382.0/1482.0)
Number of Leaves : 2
Size of the tree : 3
Dla dwóch kierunków i dwóch skal drzewo osiąga rozmiar 89 węzłów, ale za to błąd nieco się zmniejsza – do poziomu 0,092.
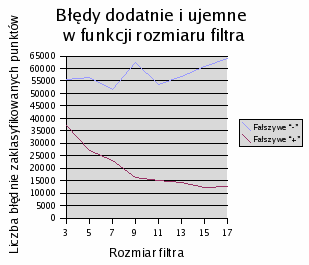
Na poniższym wykresie przedstawiono wyniki pomiarów dla obrazu 1-90.jpg, powstałego przez obrót obrazu 1.jpg o 90°.
W
tym przypadku pogorszyła się nieco trafność klasyfikowania (średni
błąd, z pominięciem pojedynczej skali, wyniósł ok. 0,115 wobec
0,095 w poprzednim pomiarze). Ogólnie kształt wykresu
potwierdza poprzednie obserwacje – nie ma monotonicznej
zależności między liczbą skal, liczbą orientacji i błędem
klasyfikowania.
[1] Lianping Chen, Guojun Lu, Dengsheng Zhang, "Effects of Different Gabor Filter Parameters on Image Retrieval by Texture".