Wykorzystanie systemu GPVIS do rozpoznawania twarzy
Wykonawcy: inż. Tomasz Bruzda, inż. Jacek Woźniak
Konsultacja: dr inż. Krzysztof Krawiec
Projekt wykonany w ramach laboratorium przedmiotu Rozpoznawanie Obrazów
Zakład Inteligentnych Systemów Wspomagania Decyzji
Instytut Informatyki
Politechnika Poznańska
1. Wstęp
Celem projektu było stworzenie aplikacji do rozpoznawania twarzy. W tym celu został wykorzystany system GPVIS, który umożliwił rozwiązanie problemu przy pomocy algorytmu programowania genetycznego – system na podstawie stworzonej gramatyki generował kolejne rozwiązania ( osobniki będące drzewami operatorów ), które podlegały ocenie ze względu na trafność decyzji na zbiorze uczącym.
2. Przebieg procesu uczenia
System GPVIS został stworzony do przeprowadzania kolejnych testów na pojedynczych obrazach, natomiast w problemie rozpoznawania twarzy realizowana jest identyfikacja osób, a więc porównania otrzymanych zdjęć z osobami zapamiętanymi w bazie danych ( w postaci ich zdjęć lub też opisu w innej formie ). Aby zminimalizować liczbę zmian w systemie GPVIS postanowiliśmy na każdym obrazie umieścić obok siebie zdjęcia dwóch osób, natomiast zadaniem testowanych osobników było ustalenie, czy jest to ta sama osoba, czy też inna.
a ) gramatyka
Pierwszym krokiem było stworzenie odpowiedniej gramatyki ( i operatorów ), odpowiadającej rozwiązanie opisywanego problemu. Została ona zdefiniowana w następujący sposób :
tbool mlog : Cmpop numexp num2
| Cmpop numexp numexp PREFER
| Or mlog mlog
| And mlog mlog
;
t Cmpop : < | > ;
t And : and ;
t Or : or ;
tfloat numexp : Arop numexp numexp
| Croi2num roi PREFER
;
t Arop : + | - ;
tconst num2 : Num ;
t Num : num ;
t Croi2num : avg ;
troi roi : LRoiFromNum num2 num2 num2 num2
| RRoiFromNum num2 num2 num2 num2
;
t LRoiFromNum : labsRoiN ;
t RRoiFromNum : rabsRoiN ;
Wynikiem działania osobnika populacji na obrazie zawierającym zdjęcia dwóch osób jest wartość logiczna będąca decyzją, czy na obrazie umieszczono zdjęcia tej samej osoby, czy też są to zdjęcia różnych osób. Operatorami logicznymi są operatory porównania oraz operacji < i >, wszystkie one działają na stałych liczbowych lub liczbach będących wynikiem działania na obrazie. Zdefiniowany został tylko jeden operator na obrazie - wyciąganie średniej z prostokąta. Prostokąt jest tworzony za pomocą jednego z dwóch operatorów (labsRoiN i rabsRoiN), odwołujących się odpowiednio do lewego i prawego zdjęcia umieszczonego na obrazie. Jako parametry podawane są cztery liczby, będące procentowymi odchyleniami od środka obrazu w poziomie i w pionie pomnożonymi przez 10.
Zarówno wynik działania na obrazie jak i parametr operatora tworzenia prostokąta są liczbami całkowitymi, jednak są one zdefiniowane jako różne typy, co ma zapobiec podmienianiu współrzędnych prostokąta wynikami działania do obrazie – prowadziło to do dużych spadków trafności klasyfikacji na zbiorze testującym. Cała gramatyka została ograniczona jedynie do niezbędnych operatorów, co ma zapewnić odpowiednie ukierunkowanie – eliminuje ona możliwość powstania bezsensownych konstrukcji w generowanych osobnikach.
b ) ocenianie osobników
Podczas oceniania wartość osobnika jest zmieniana na podstawie trafności podjętych decyzji. Każdorazowy test na obrazie modyfikuje wartość oceniającego go osobnika zgodnie z wartościami przedstawionymi w poniższej tabeli :
| | decyzja: różne osoby | decyzja : „ta sama osoba" |
| różne osoby | 2.0 | -1.0 |
| ta sama osoba | -2.0 | 1.0 |
Wartości w powyższej tabeli zostały tak dobrane, aby spełniać następujące warunki :
- mniej szkodliwe jest uznanie zdjęć rożnych osób za zdjęcia tej samej osoby niż odwrotnie, gdyż w ten sposób dostaniemy na końcu zbiór n zdjęć osób potencjalnie podobnych do szukanej, gdzie n byłoby znacznie mniejsze od rozmiaru całej bazy danych, a więc znacznie ograniczylibyśmy zbiór potencjalnie podobnych osób; natomiast gdybyśmy uznali zdjęcia tej samej osoby za zdjęcia różnych osób, to usunęlibyśmy rozwiązanie problemu z tego zawężonego zbioru
- oceny poprawnych decyzji zostały ustalone w ten sposób, aby sumy ocen w kolumnach była taka sama – w ten sposób nie preferujemy żadnej z dwóch możliwych odpowiedzi; jeśliby tak nie było, to wysokie oceny mogłyby być uzyskane przez osobniki, które cały czas odpowiadają np. „ta sama osoba”.
3. Modyfikacje w systemie GPVIS
- Zbiór obrazów ( zarówno uczący jak i testujący ) jest wczytywany do wektora obiektów typu CMNISTPureImage. Obrazy przechowywane są w odpowiednim katalogu w plikach *.png – wybraliśmy ten format, gdyż jest on bezstratny, charakteryzuje się dobrą kompresją i obsługuje różne sposoby kodowania koloru ( truecolor, palety, odcienie szarości). Do wczytywania obrazów w tym formacie wykorzystaliśmy biblioteki libpng i zlib. Dodaliśmy funkcję CreateSet(), która wczytuje z aktualnego katalogu (jest on ustawiany przed jej wywołaniem) podaną liczbę obrazów należących do klasy decyzyjnej 0 ( różne osoby ) lub 1 ( te same osoby ). Do projektu dodaliśmy także funkcję getlabel(), która na podstawie nazwy pliku decyduje, do której z klas decyzyjnych należy przykład. Obrazy wchodzące w skład zbioru uczącego i testującego mają na końcu nazwy dodany numer klasy, np. ant_exp.13ant_exp.19-1.png dla klasy 1 lub will_exp.15chr_exp.16-0.png dla klasy 0. Do tworzenia zbiorów uczących i testujących służy program imgmix opisany w następnym punkcie.
- Zmienione zostały funkcje Test() oraz Train() w ten sposób, aby do wczytywania obrazów wykorzystywały funkcję CreateSet(). Najpierw wczytywana jest pierwsza klasa, później druga, a na końcu te dwa wektory są łączone.
- Nie została podmieniona funkcja TestOne(), dlatego ten tryb testowania nie jest odstępny w systemie dostosowanym do rozpoznawania twarzy.
- Na początku funkcji main() dodaliśmy wywołanie funkcji inicjującej generator liczb losowy z parametrem będącym wartością czasu systemowego wyrażonego w milisekundach. Jest to funkcja charakterystyczna dla systemu Windows.
- Zmodyfikowana została funkcja oceniająca osobniki ( zgodnie z przedstawioną wyżej tabelą ). Do funkcji RunRec() dodaliśmy definicje nowych operatorów ( średnia oraz tworzenie prostokątów ). Nowe terminale, nieterminale i typy zostały dodane do odpowiednich tablic w pliku const.cpp.
- Zmieniona została także funkcja określająca zależność od obrazu – dodany został warunek zależności operatora średniej od obrazu.
- W pliku konfiguracyjnym zakres generatora liczb losowych został ustalony na 10. Dzięki temu zakres prostokąta waha się od 0 do 100% rozmiaru pojedynczego zdjęcia. Zakresu generatora nie należy modyfikować. Rozmiary prostokąta zostały podane względnie do wymiarów zdjęć aby zapewnić uniwersalność generowanych rozwiązań – będą one klasyfikować także obrazy testujące o rozmiarach różniących się od rozmiarów obrazów uczących.
- W metodzie Statistics klasy CGAEngineAbstract informacje o numerze iteracji są wypisywane zarówno na standardowe wyjście i na cerr, aby podczas przekierowywania komunikatów do pliku można było na bieżąco obserwować numer iteracji i informacje o jakości rozwiązań.
- Wszystkie miejsca, w których zmieniony został projekt, zostały opatrzone komentarzem FACES_MOD oraz dodatkowym wyjaśnieniem.
4. Opis programu imgmix
W celu stworzenia zbioru uczącego lub testującego należy przygotować zbiór zdjęć twarzy różnych osób nazwanych wg schematu identyfikator_osoby.numer.png. Wszystkie zdjęcia powinny mieć ten sam rozmiar i kolor w postaci 256 odcieni szarości.
Program łączy poszczególne pary zdjęć w jeden obraz, w którym zdjęcia zostają umieszczone obok siebie. Plikowi wyjściowemu w formacie png zostaje nadana nazwa wg schematu id_osoby1.nr1.id_osoby2.nr2-klasa.png, gdzie klasa to 1 lub 0 w zależności od tego, czy jest to ta sama osoba czy też nie.
Program imgmix wczytuje z aktualnego plik konfiguracyjny imgmix.cfg, w którym zawarte są informacje o sposobie działania programu. Linie komentarza zaczynają się od znaku #, natomiast linie zawierające słowa kluczowe od znaku @.
Poniżej zamieszczamy opis słów kluczowych pliku imgmix.cfg :
- filetype: określa maskę dla nazw plików, które będą ze sobą łączone
- srcdir: określa bezwzględną ścieżkę do katalogu zawierającego zdjęcia do połączenia
- dstdir: określa bezwzględną ścieżkę do katalogu, w którym zostaną umieszczone wygenerowane pliki
- mode: wartość all oznacza, że mają być wygenerowane wszystkie kombinacje par, natomiast wartość random, że pary będą wybierane losowo, a ich liczba określona jest parametrem imgcount
- imgcount: w przypadku gdy wartość parametru mode wynosi random, liczba podana po słowie kluczowym imcount określa, ile par połączonych zdjęć ma zostać wygenerowanych
- imgtype: definiuje do jakiej klasy mają należej wygenerowane obrazy; wartość equal oznacza klasę 1, czyli tą samą osobę, wartość diff różne osoby, a wartość all oznacza, że obrazy będą generowane bez względu na ich przynależność do którejś z klas decyzyjnych
- hist: jeśli wartość podana po słowie hist jest nieujemna to przed połączeniem histogram każdego zdjęcia zostanie wyrównany wg następujących wzorów :
- p jest parametrem przekazanym do funkcji wyrównującej histogram
- hist jest histogramem obrazu wejściowego
- hist[i] jest wartością histogramu dla wartości i odcienia szarości
- pict jest obrazem wejściowym
- pict[i] jest i-tym punktem obrazu wejściowego
- - width: określa szerokość obrazu wynikowego, do której zostaną zmniejszone/zwiększone połączone obrazy; wartość po parametrze width musi być liczbą parzystą; jeśli parametr width będzie miał wartość 0 to szerokość zdjęć nie zostanie zmieniona
- - height: określa wysokość obrazu wynikowego, do której zostaną zmniejszone/zwiększone połączone obrazy; jeśli parametr height będzie miał wartość 0 to wysokość zdjęć nie zostanie zmieniona
Istnieją dwie wersje programu łączącego obrazy – imgmix oraz imgmixb. Druga wersja nie sprawdza, czy z dostarczonego przez użytkownika zbioru zdjęć wejściowych da się wygenerować żądaną przez niego liczbę obrazów, przez co działa szybciej dla większych zbiorów, jednak zakłada poprawność parametrów podanych przez użytkownika.
W celu stworzenia zbioru uczącego należy odpowiednio zmodyfikować plik konfiguracyjny ustawiając parametr mode na random, imgcount na żądany rozmiar klasy, imgtype na equal, wygenerować obrazy, zmienić imgtype na diff i wygenerować drugą z klas decyzyjnych.
5. Przykładowe wyniki
Po zaimplementowaniu metody testującej rozwiązania przeprowadziliśmy dwa testy. Obrazy wejściowe miały rozmiary 40x20.
Do pierwszego z testów użyliśmy bazy twarzy grimface. Liczność każdej klasy w zbiorze uczącym wynosiła 200, w zbiorze testującym – 1000. Wielkość populacji ustaliliśmy na 200 osobników, a liczbę iteracji algorytmu genetycznego na 150. Otrzymaliśmy następujące wyniki :
Evaluation (0) on training set:
Acc: 0.843 Total: 446
191 32
38 185
Decision credibility: 0.834 0.853
Evaluation (0) on test set:
Acc: 0.755 Total: 2000
792 208
282 718
Decision credibility: 0.737 0.775
BEST OVERALL SOLUTION:
Evaluation on training set:1.715
Evaluation on test set:1.275
Na poniższym wykresie przedstawiamy jak zmieniała się ocena populacji w kolejnych iteracjach eksperymentu :
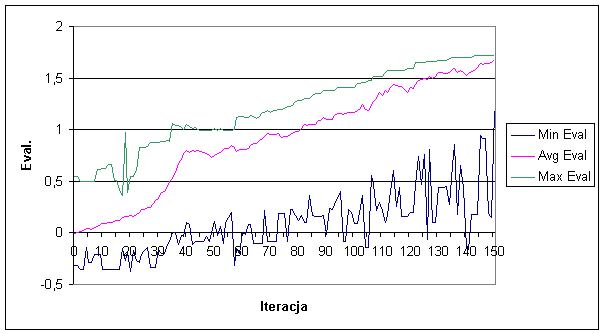 Ocena najlepszego osobnika zwiększała się od 60-tej iteraracji w miarę jednostajnie aż do końca eksperymentu.
Do drugiego z testów użyliśmy bazy twarzy faces94. Liczność każdej klasy w zbiorze uczącym wynosiła 200, w zbiorze testującym – 1000. Wielkość populacji ustaliliśmy na 200 osobników, a liczbę iteracji algorytmu genetycznego na 50. Otrzymaliśmy następujące wyniki :
Ocena najlepszego osobnika zwiększała się od 60-tej iteraracji w miarę jednostajnie aż do końca eksperymentu.
Do drugiego z testów użyliśmy bazy twarzy faces94. Liczność każdej klasy w zbiorze uczącym wynosiła 200, w zbiorze testującym – 1000. Wielkość populacji ustaliliśmy na 200 osobników, a liczbę iteracji algorytmu genetycznego na 50. Otrzymaliśmy następujące wyniki :
Evaluation (0) on training set:
Acc: 0.845 Total: 400
174 26
36 164
Decision credibility: 0.829 0.863
Evaluation (0) on test set:
Acc: 0.802 Total: 2000
827 173
222 778
Decision credibility: 0.788 0.818
BEST OVERALL SOLUTION:
Evaluation on training set:1.725
Evaluation on test set:1.513
Na poniższym wykresie przedstawiamy jak zmieniała się ocena populacji w kolejnych iteracjach eksperymentu :
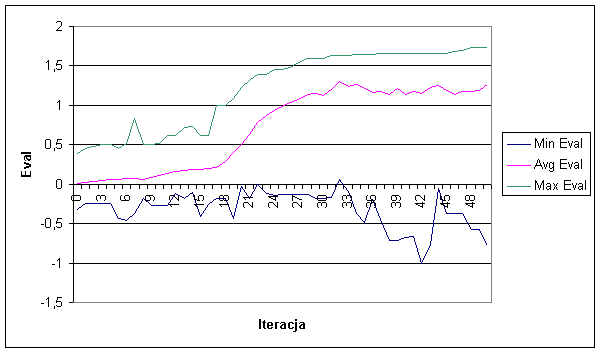 Baza użyta w tym eksperymencie wydaje się prostsza do opanowania przez system. Dobry wynik został uzyskany już w iteracji 30-tej.
Baza użyta w tym eksperymencie wydaje się prostsza do opanowania przez system. Dobry wynik został uzyskany już w iteracji 30-tej.
6. Uwagi
W obecnej postaci system nie sprawdza, czy osoba przedstawiona na dostarczonym mu nowym zdjęciu istnieje już w bazie danych, jednak proces ten przebiegałby tak, że należałoby łączyć nowe zdjęcie ze zdjęciami osób z bazy danych i przeprowadzić fazę testowania. W celu poprawy wyników można by było zagregować wyniki wygenerowane przez kilka osobników uzyskanych w różnych procesach uczenia.
Przedstawiona tu gramatyka jest bardzo prosta. Isnieje wiele możliwości jej rozszerzenia, np. dodanie operatorów działających na tym samym obszarze na lewym i prawym zdjęciu jednocześnie lub zastąpienie operatora wyciągania średniej operatorem wyliczającym odchylenie od średniej wartości w obszarze lub zdjęciu.